
MuleSoft RTF: Tutorial, Best Practices & Examples
Running integrations at scale requires a platform that remains reliable, flexible, and easy to manage across environments. The MuleSoft Runtime Fabric (RTF) addresses this requirement by enabling Mule applications to run on Kubernetes while staying fully integrated with the Anypoint Platform. It provides a standardized runtime layer that combines container orchestration with centralized API management, security, and observability.
This article examines the architecture of RTF, its operation in real-world environments, and the best practices organizations can follow to deploy, secure, and manage Mule applications effectively.
Summary of key Mulesoft RTF concepts
{{banner-large-graph="/banners"}}
Kubernetes fundamentals for RTF
MuleSoft Runtime Fabric is built on top of Kubernetes. While deep Kubernetes expertise is not required to use RTF, understanding a few core concepts makes it much easier to reason about how Mule applications are deployed, scaled, and managed.
At its core, Kubernetes is responsible for running containerized applications reliably and efficiently. It handles scheduling, scaling, restarts, and network connectivity, allowing platforms like Runtime Fabric to focus on higher-level concerns such as governance, security, and observability.
Containers and images
A container packages an application together with everything it needs to run, including libraries and runtime dependencies. In the context of RTF, Mule applications are packaged as container images that can be deployed consistently across environments. This containerized approach ensures that a Mule application behaves consistently in development, testing, and production, regardless of its deployment location. Kubernetes uses these images as the basic building blocks for running applications within the cluster.
Pods
Kubernetes does not run containers directly. Instead, containers are grouped into pods, which are the smallest deployable units in Kubernetes. In the Runtime Fabric, each Mule application runs inside one or more pods. These pods encapsulate the Mule runtime along with any supporting components required at runtime. When application demand increases, Kubernetes can create additional pod instances, allowing the application to scale horizontally without manual intervention.
Nodes and clusters
Pods run on nodes, which are the worker machines (either virtual or physical) that make up a Kubernetes cluster. A collection of nodes forms the runtime environment where Mule applications execute. RTF relies on this cluster model to distribute workloads, enhance fault tolerance, and ensure that applications continue to run even if individual nodes fail.
Networking and ingress
Kubernetes provides built-in networking capabilities that allow applications to communicate with each other and with external systems. Ingress components act as the entry point for incoming traffic, routing requests to the appropriate Mule application pods.
In Runtime Fabric, ingress plays a crucial role in securely exposing APIs while enabling traffic management, TLS termination, and integration with platform-level security controls. By abstracting much of the underlying Kubernetes complexity, RTF enables integration teams to benefit from container orchestration without directly managing it while still retaining the scalability and resilience that Kubernetes provides.
The diagram below shows how Kubernetes control plane components, worker nodes, pods, and ingress work together in a Runtime Fabric deployment.
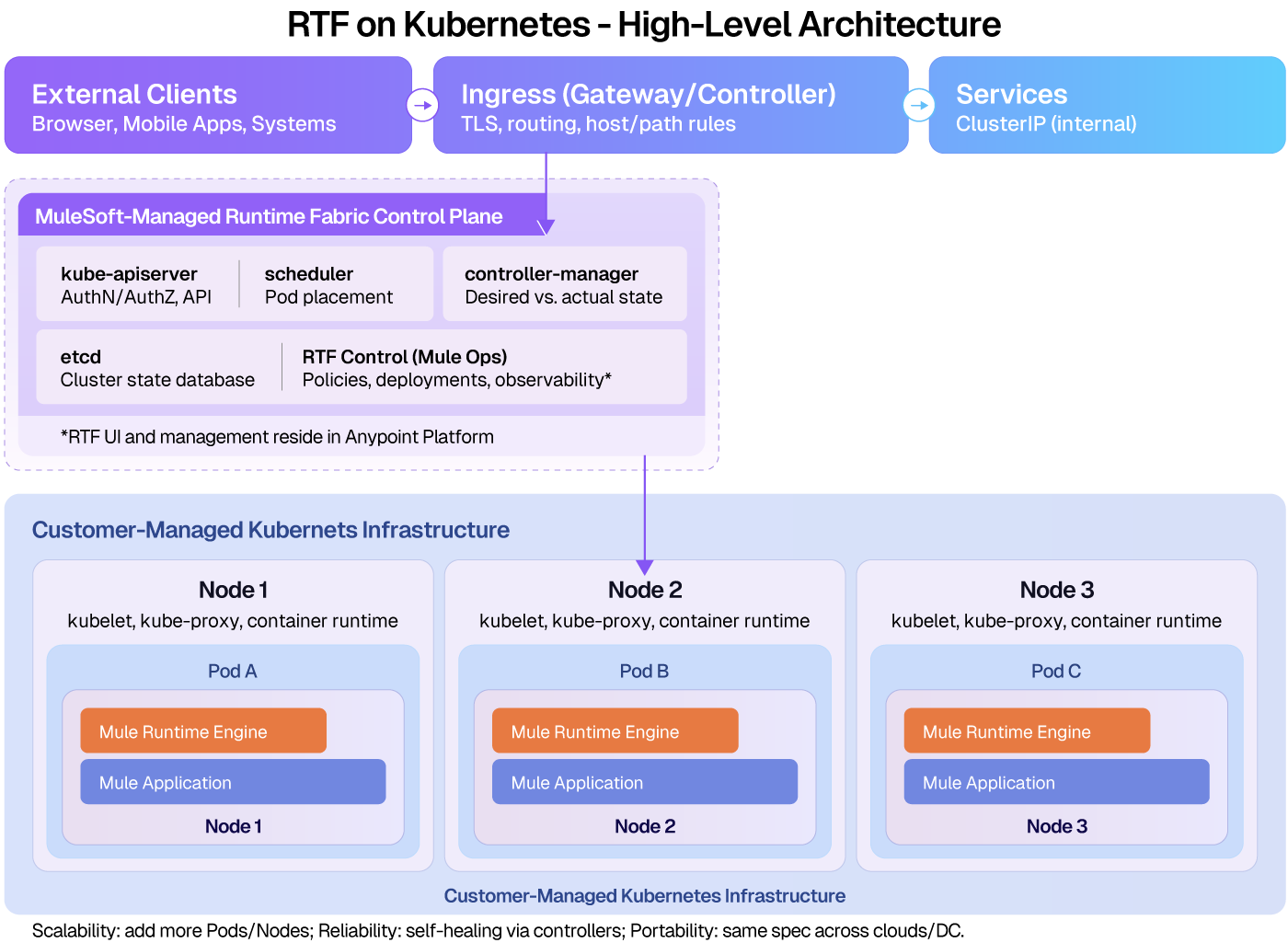
How Kubernetes works in Runtime Fabric
At a high level, external client requests enter the cluster through the ingress layer, where routing rules and TLS termination are applied. Traffic is then forwarded to Kubernetes services, which provide stable network endpoints for Mule application pods even as those pods scale or restart.
The Kubernetes control plane is responsible for maintaining the desired state of the cluster, including pod placement, health monitoring, and recovery. RTF integrates with this control plane through Kubernetes controllers and agents, allowing Anypoint Platform to manage deployments, policies, and observability without requiring direct administrative access to the cluster.
Mule applications run within pods on worker nodes inside the RTF runtime zone. Kubernetes handles scheduling and rescheduling of these pods across nodes, while Runtime Fabric ensures consistent runtime configuration, policy enforcement, and operational visibility across environments.
RTF architecture and core components
The Runtime Fabric architecture comprises a control plane, a data plane, and a Runtime Fabric agent. These components work together to manage the lifecycle, scaling, and governance of Mule applications running on Kubernetes-based infrastructure.
Control plane
The control plane resides within Anypoint Platform and represents the centralized management layer for Runtime Fabric. It maintains the desired state of applications, including deployment configuration, runtime settings, and applied policies.
From the control plane, teams define how Mule applications should be deployed and governed. This includes configuring runtime versions, resource allocation, and API policies as well as accessing operational visibility through monitoring and alerts. The control plane does not directly interact with Kubernetes resources; instead, it communicates intent to the Runtime Fabric agent.
Data plane
The data plane represents the runtime environment where Mule applications execute. It consists of a Kubernetes cluster or supported infrastructure where Runtime Fabric is installed. Within the data plane, Mule applications run inside pods on worker nodes, handling live traffic. Kubernetes manages scheduling, restarts, and scaling of these workloads, while Runtime Fabric ensures that application configuration and behavior remain aligned with the definitions in the control plane. Because the data plane is customer-managed, organizations retain control over infrastructure placement, networking, and capacity planning while still operating under centralized platform governance.
Runtime Fabric agent
The Runtime Fabric agent operates within the data plane, serving as the communication layer between the control plane and the runtime environment. It establishes a secure, outbound connection to Anypoint Platform. When changes are made to the control plane, such as deploying a new application version or updating configuration, the agent translates them into Kubernetes-native operations. This includes creating or updating pods, applying configuration values, and coordinating ingress or service updates as required. By mediating all interactions, the agent enables Anypoint Platform to manage application lifecycles without direct access to the Kubernetes cluster, thereby supporting a secure, controlled operational model.
How the components work together
In practice, application definitions and governance settings are created in the control plane. The Runtime Fabric agent retrieves these definitions and applies them within the data plane using Kubernetes mechanisms. Kubernetes then ensures that application workloads are scheduled, scaled, and kept running according to the defined state.
The diagram below illustrates the interaction between the control plane, data plane, and Runtime Fabric agent within a Runtime Fabric deployment, as well as how Kubernetes components facilitate application execution under centralized governance.
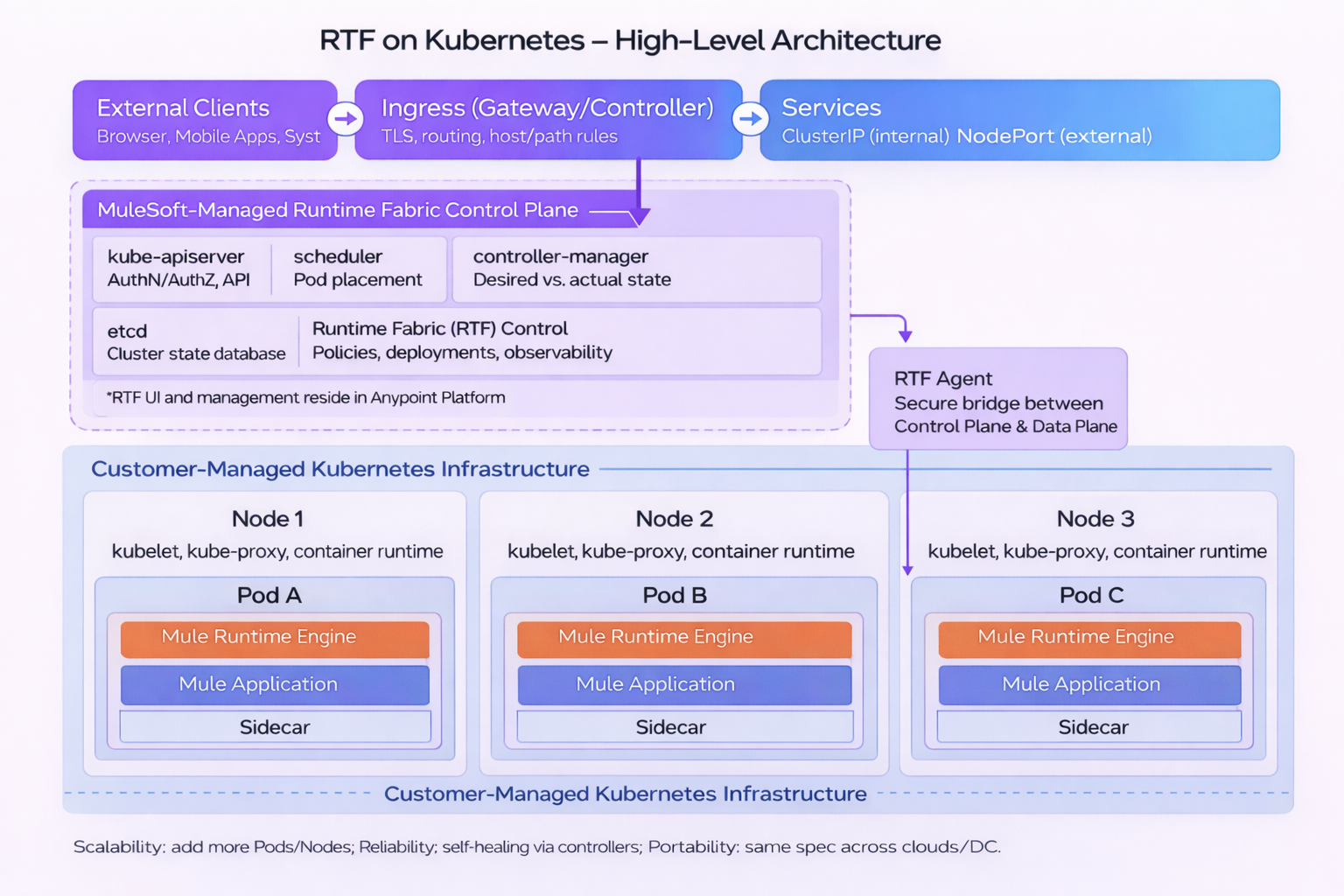
RTF requirements and limitations
Deploying MuleSoft RTF requires meeting a defined set of infrastructure and platform prerequisites. These requirements ensure that RTF deployments remain stable, scalable, and compatible with the versions and configurations supported by MuleSoft.
Understanding these requirements up front helps teams plan deployments more effectively and avoid issues related to unsupported configurations or operational gaps.
Supported deployment options
Runtime Fabric can be deployed using two primary models. The first is CloudHub 2.0, where MuleSoft manages the underlying infrastructure and Kubernetes environment. This option minimizes operational responsibility and provides a managed experience.
The second option is Anypoint Runtime Fabric on self-managed Kubernetes (BYOK). In this model, organizations install and operate RTF on their own Kubernetes clusters. This approach provides greater control over infrastructure, networking, and compliance, but also requires teams to manage more operational components directly.
Kubernetes cluster requirements
For BYOK deployments, the Kubernetes cluster must align with MuleSoft’s officially supported versions, as documented in the Runtime Fabric release notes. Unsupported Kubernetes versions or configurations may lead to installation failures or unpredictable behavior.
All cluster nodes must meet the minimum requirements for CPU, memory, and storage to support Mule runtime workloads. Additionally, outbound network connectivity to the Anypoint control plane is required so that the Runtime Fabric agent can securely communicate deployment and management information.
Platform-level limitations
Each Runtime Fabric environment maps to a single Kubernetes cluster. There is no built-in capability to span a single RTF environment across multiple clusters or regions. Runtime Fabric also does not provide native cross-cluster or multi-region synchronization. High availability and disaster recovery strategies must therefore be designed at the infrastructure and deployment level rather than relying on automatic platform replication.
For self-managed Kubernetes deployments, networking components such as DNS configuration, load balancers, and ingress controllers must be provisioned and maintained externally. Runtime Fabric integrates with these components but does not automatically create or manage them.
Upgrade and scaling considerations
Runtime Fabric and Mule runtime versions must remain aligned with MuleSoft’s supported compatibility matrix. Skipping major versions during upgrades is not recommended because it can introduce compatibility or stability issues.
Application scaling within RTF depends on the available cluster capacity and the number of vCores allocated to Mule runtimes. Maintaining at least 3 worker nodes per cluster is recommended to support high availability and fault tolerance.
While Kubernetes supports horizontal scaling, scaling actions are handled at the Kubernetes layer. The Anypoint control plane does not automatically scale workloads; instead, scaling behavior must be configured using Kubernetes mechanisms, such as replica sets or autoscaling policies.
Feature parity with CloudHub 2.0
Runtime Fabric provides functionality comparable to CloudHub 2.0 for running and managing Mule applications. However, some services that are fully managed in CloudHub 2.0, such as load balancing, global failover, or centralized logging, may require additional configuration or third-party integrations in BYOK environments.
CloudHub 2.0 vs Runtime Fabric (RTF) Deployment Comparison
While both CloudHub 2.0 and Runtime Fabric provide a consistent Mule application runtime and centralized governance, they differ primarily in how they manage infrastructure and operational responsibilities.
Isolating workloads with namespaces and pods
Runtime Fabric relies on Kubernetes namespaces and pods to isolate Mule application workloads and manage resource usage across environments. This isolation is essential when multiple applications or teams share the same cluster.
Namespaces provide logical separation within a Kubernetes cluster. In Runtime Fabric, namespaces are commonly used to distinguish environments such as development, testing, and production or to separate workloads belonging to different teams or business units. This separation helps prevent configuration overlap and limits the impact of changes made in one environment on others.
Within each namespace, Mule applications run inside pods. A pod, the smallest execution unit in Kubernetes, encapsulates the Mule runtime and its supporting components. By running applications in dedicated pods, Runtime Fabric ensures that failures, restarts, or scaling events are isolated to the affected application rather than impacting the entire cluster.
Resource allocation is also managed at the pod level. CPU, memory, and vCore limits defined for each Mule application ensure predictable performance and prevent resource contention between workloads. Kubernetes enforces these limits at runtime, while Runtime Fabric aligns application configuration with the values defined in Anypoint Platform.
Together, namespaces and pods provide a structured isolation model that supports multi-tenant usage, operational stability, and controlled scaling.
{{banner-large="/banners"}}
Securing APIs deployed on RTF
Securing APIs deployed on Runtime Fabric involves controls at multiple layers, spanning network communication, platform governance, and credential management. Runtime Fabric integrates with both Kubernetes-native security mechanisms and Anypoint Platform capabilities to support a layered security model.
Secure communication with TLS and mTLS
All external traffic entering a Runtime Fabric environment is typically secured using Transport Layer Security (TLS), which encrypts data exchanged between clients and APIs in transit, protecting it from interception or tampering. For scenarios that require stronger identity verification, mutual TLS (mTLS) can be utilized. With mTLS, both the client and the server present certificates during the handshake process, allowing each party to verify the other’s identity before communication is established. In Runtime Fabric deployments, TLS and mTLS are commonly enforced at the ingress layer, before traffic reaches Mule application pods.
Network-level access controls
In addition to encrypted communication, network-level access to APIs can be restricted. In Runtime Fabric environments, ingress controllers and external load balancers are commonly configured with firewall rules, IP allowlists, or Web Application Firewall (WAF) integrations. These controls help limit exposure by ensuring that only approved sources can reach the ingress layer. Runtime Fabric integrates with these networking components but does not automatically provision them in self-managed Kubernetes environments, leaving their configuration as part of the overall platform security design.
Centralized API security and governance
Runtime Fabric relies on Anypoint API Manager to enforce API-level security policies consistently across deployments. Policies such as OAuth 2.0, client ID enforcement, rate limiting, and threat protection are applied centrally and enforced at runtime without requiring changes to application code. This centralized approach allows security rules to be managed independently of deployment topology. Whether APIs are running on Runtime Fabric, CloudHub, or other supported targets, the same governance model applies.
Secure credential and secret management
Sensitive information such as credentials, tokens, and certificates must be handled securely in Runtime Fabric environments. Rather than embedding secrets directly in application configuration files, Runtime Fabric supports using Kubernetes Secrets and secure property management mechanisms. These secrets are injected into Mule applications at runtime, reducing the risk of exposure in source control systems or logs. Managing credentials through dedicated secret stores also supports rotation and access control without requiring redeployment of the application.
Security Architecture in Runtime Fabric
Runtime Fabric applies security controls across multiple layers, separating network access, runtime isolation, and policy enforcement responsibilities. The architecture below illustrates how these responsibilities are distributed across the ingress, Kubernetes, and Anypoint policy layers.
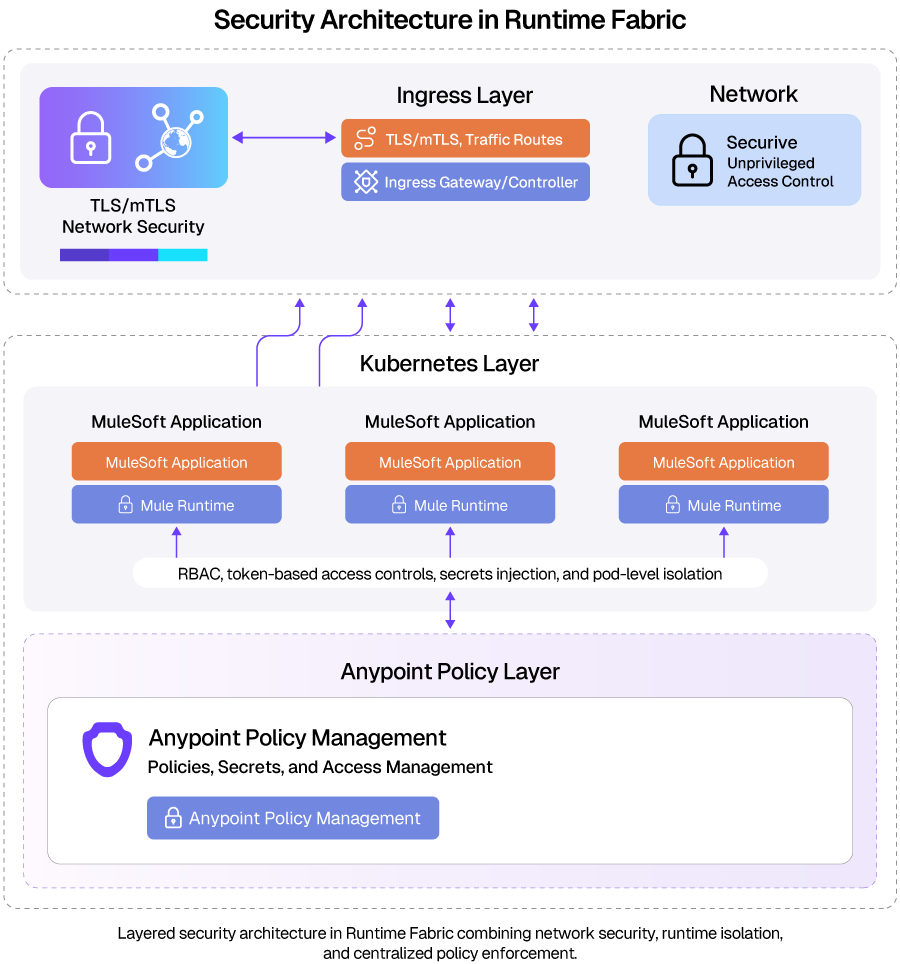
Ingress Layer
The ingress layer serves as the controlled entry point for external traffic into the Runtime Fabric environment. It manages request routing and enforces network-level security controls before traffic reaches the Kubernetes cluster. This layer defines the boundary between external clients and internal runtime workloads.
Kubernetes Layer
Within the Kubernetes layer, Mule applications run in isolated pods managed by the cluster. Security at this layer focuses on enforcing workload isolation, controlling access within the cluster, and securely injecting runtime configuration. These controls apply uniformly across applications sharing the same cluster infrastructure.
Anypoint Policy Layer
The Anypoint policy layer centralizes API-level security enforcement across all Mule applications deployed on Runtime Fabric. Policies are applied independently of the runtime and infrastructure layers, allowing consistent governance across environments. This layer integrates with the Anypoint Platform to manage policy configuration and API boundary access controls.
Monitoring and observability in RTF
Operating Mule applications on Runtime Fabric requires visibility into application behavior, resource usage, and overall platform health. Runtime Fabric supports observability by integrating Mule runtime metrics and logs with both Anypoint Platform tools and external monitoring systems. This visibility enables teams to identify issues early, understand runtime behavior, and troubleshoot problems without requiring direct access to the underlying Kubernetes cluster.
Logging and metrics collection
Mule applications running on Runtime Fabric generate logs and runtime metrics that provide insight into application execution. These include application logs, error traces, and performance indicators such as CPU and memory usage.
Runtime Fabric supports forwarding logs and metrics to Anypoint Monitoring, where they can be viewed through centralized dashboards. In self-managed environments, logs and metrics can also be integrated with external systems such as ELK or Splunk using standard Kubernetes logging and forwarding mechanisms.
Dashboards and alerts
Dashboards provide a consolidated view of application health and performance across Runtime Fabric environments. Metrics such as response times, error rates, and resource utilization can be visualized to track trends and identify abnormal behavior.
Alerting mechanisms can be configured to notify teams when predefined thresholds are crossed. These alerts support operational workflows by highlighting potential issues before they escalate into service disruptions.
Platform-level visibility
Runtime Fabric maintains visibility across environments by associating runtime metrics and logs with application and environment context defined in Anypoint Platform. This allows teams to correlate operational data with deployment versions, configurations, and applied policies. Because observability is centralized at the platform level, teams can consistently monitor applications across different deployment targets without relying solely on environment-specific tooling.
Achieving high availability (HA) and enabling disaster recovery (DR)
High availability and disaster recovery in Runtime Fabric are enabled by a combination of Kubernetes orchestration, infrastructure redundancy, and persistent data management. Rather than relying on a single mechanism, Runtime Fabric distributes responsibility across multiple layers to reduce the impact of failures.
Control plane resilience
Runtime Fabric environments are designed to operate with multiple controller nodes. These controllers form the control plane, which maintains cluster state and coordinates orchestration activities.
Using an odd number of controller nodes supports quorum-based decision-making. If one controller becomes unavailable, the remaining controllers continue operating, keeping cluster management functions available without disruption.
Application-level availability
Mule applications deployed on Runtime Fabric run as pods distributed across worker nodes. Kubernetes monitors the health of these pods and automatically restarts or reschedules them if failures occur. When multiple replicas of an application are deployed, traffic can be distributed across these instances. This approach helps maintain availability during node failures or rolling updates, eliminating the need for manual intervention.
Node and infrastructure redundancy
Worker nodes are typically spread across failure domains such as availability zones or racks, depending on the underlying infrastructure. This distribution reduces the risk that a single infrastructure issue will affect all running applications.
If a worker node becomes unavailable, Kubernetes reschedules affected pods onto healthy nodes, allowing applications to continue processing traffic with minimal interruption.
Data durability and recovery
Stateful data used by Mule applications is stored outside application pods through persistent storage mechanisms. This ensures that data remains available even when pods are restarted or moved between nodes. Persistent storage also supports backup and restore processes as part of broader disaster recovery planning. These processes are typically implemented at the infrastructure or storage layer rather than within the Runtime Fabric control plane itself.
Disaster recovery considerations
Runtime Fabric does not provide built-in multi-region or cross-cluster synchronization. Disaster recovery strategies, therefore, depend on infrastructure design, backup policies, and deployment automation. Organizations commonly implement DR by maintaining separate Runtime Fabric environments and redeploying applications using automated pipelines when required. This approach also aligns with Kubernetes-based operational models, where recovery is driven by infrastructure readiness and configuration consistency.
Automating Mule application deployments
Automating application deployments is a core practice for operating Runtime Fabric reliably at scale. Automation reduces manual intervention, ensures consistency across environments, and supports repeatable deployment workflows.
Streamlining deployments with the Mule Maven plugin
Mule applications are commonly built and packaged using Maven-based workflows. The Mule Maven plugin plays a central role in this process by supporting packaging, versioning, and deployment of Mule applications to Runtime Fabric environments.
When integrated into CI/CD pipelines, the plugin enables automated deployment of applications as part of the release process. Deployment parameters such as environment-specific configuration values, runtime versions, and resource settings can be externalized, ensuring that the same application artifact is promoted consistently across environments.
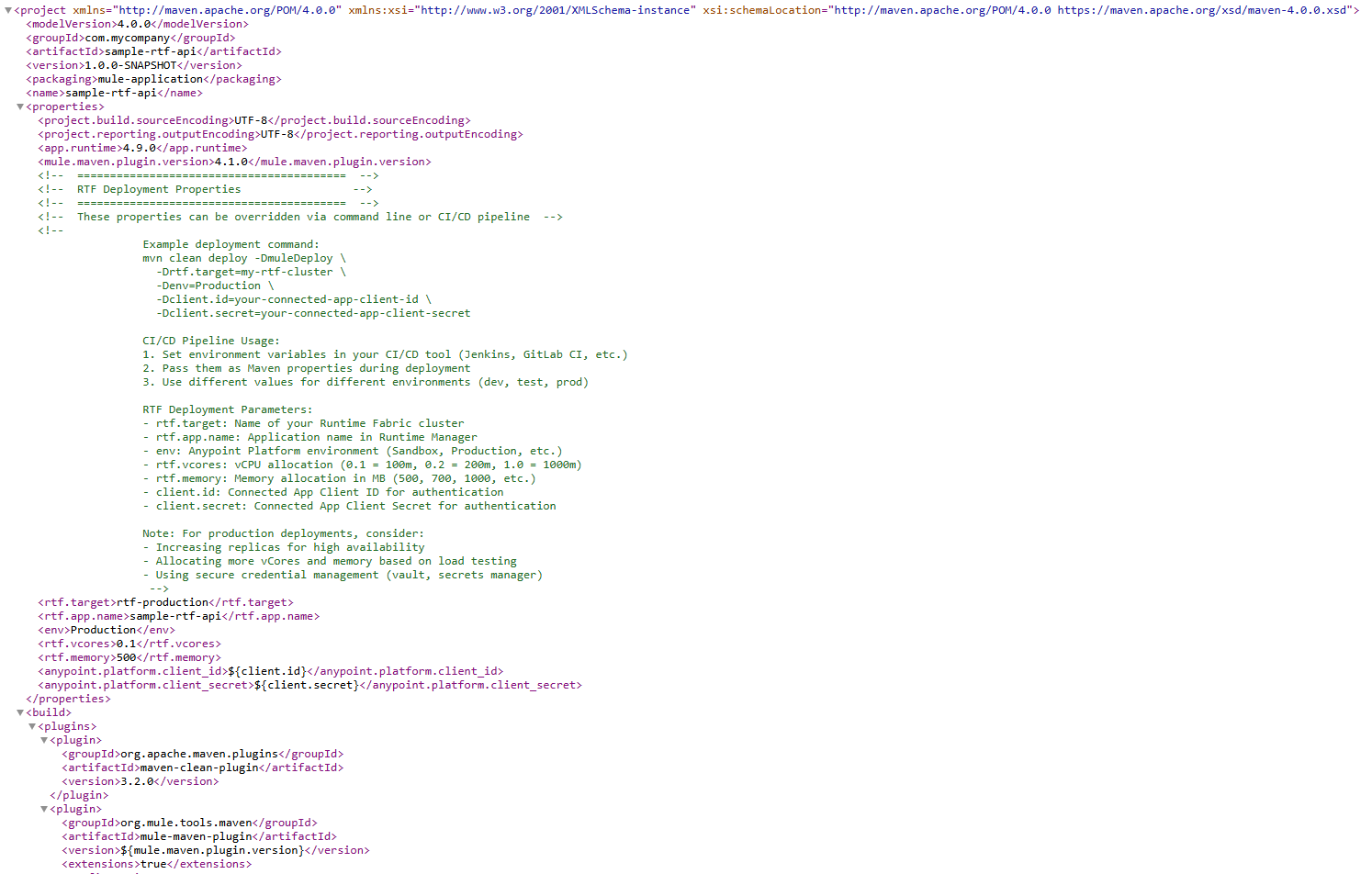
Sample POM(Project Object Model) configuration for RTF deployment
Shown below is a typical configuration snippet within the pom.xml file that demonstrates how the Mule Maven Plugin is set up to deploy to RTF:
<plugin>
<groupId>org.mule.tools.maven</groupId>
<artifactId>mule-maven-plugin</artifactId>
<version>3.8.6</version>
<extensions>true</extensions>
<configuration>
<runtimeFabricDeployment>
<uri>https://anypoint.mulesoft.com</uri>
<muleVersion>${app.runtime}</muleVersion>
<username>${username}</username>
<password>${password}</password>
<applicationName>${app.name}</applicationName>
<target>rtf</target>
<environment>${environment}</environment>
<provider>MC</provider>
<replicas>${replicas}</replicas>
<properties>
<key>value</key>
</properties>
<deploymentSettings>
<enforceDeployingReplicasAcrossNodes>false
</enforceDeployingReplicasAcrossNodes>
<updateStrategy>recreate</updateStrategy>
<clustered>false</clustered>
<forwardSslSession>false</forwardSslSession>
<lastMileSecurity>false</lastMileSecurity>
<resources>
<cpu>
<reserved>${reserved.cpu}</reserved>
<limit>${cpu.limit}</limit>
</cpu>
<memory>
<reserved>${reserved.memory}</reserved>
</memory>
</resources>
<http>
<inbound>
<publicUrl>${public.url}</publicUrl>
</inbound>
</http>
</deploymentSettings>
</runtimeFabricDeployment>
</configuration>
</plugin>AI-driven automation for MuleSoft RTF with CurieTech AI
Runtime Fabric deployments rely on a large set of configuration elements, including Maven configuration, runtime versions, resource settings, environment variables, and deployment descriptors. Managing these consistently across applications and environments can be time-consuming and error-prone, especially as the number of RTF deployments grows.
CurieTech AI supports this aspect of Runtime Fabric adoption by assisting with the generation of RTF-ready Mule application structures and deployment configurations. Based on a defined set of inputs such as runtime versions, target environments, and deployment preferences, it produces standardized project scaffolding and configuration artifacts aligned with supported RTF deployment models.
This approach enables teams to maintain consistency across environments while continuing to use their existing CI/CD pipelines for builds and deployments. By reducing the need for repeated manual configuration, it supports predictable deployments and simplifies ongoing operational maintenance without altering established deployment workflows.
The following walkthrough illustrates how to create a sample RTF API project step-by-step within the CurieTech AI platform:
- Enter the details in the prompt section and click Enter:

- Here’s a sample prompt:



- Evaluate the details in the response and confirm the requirement:

- Review the task created:
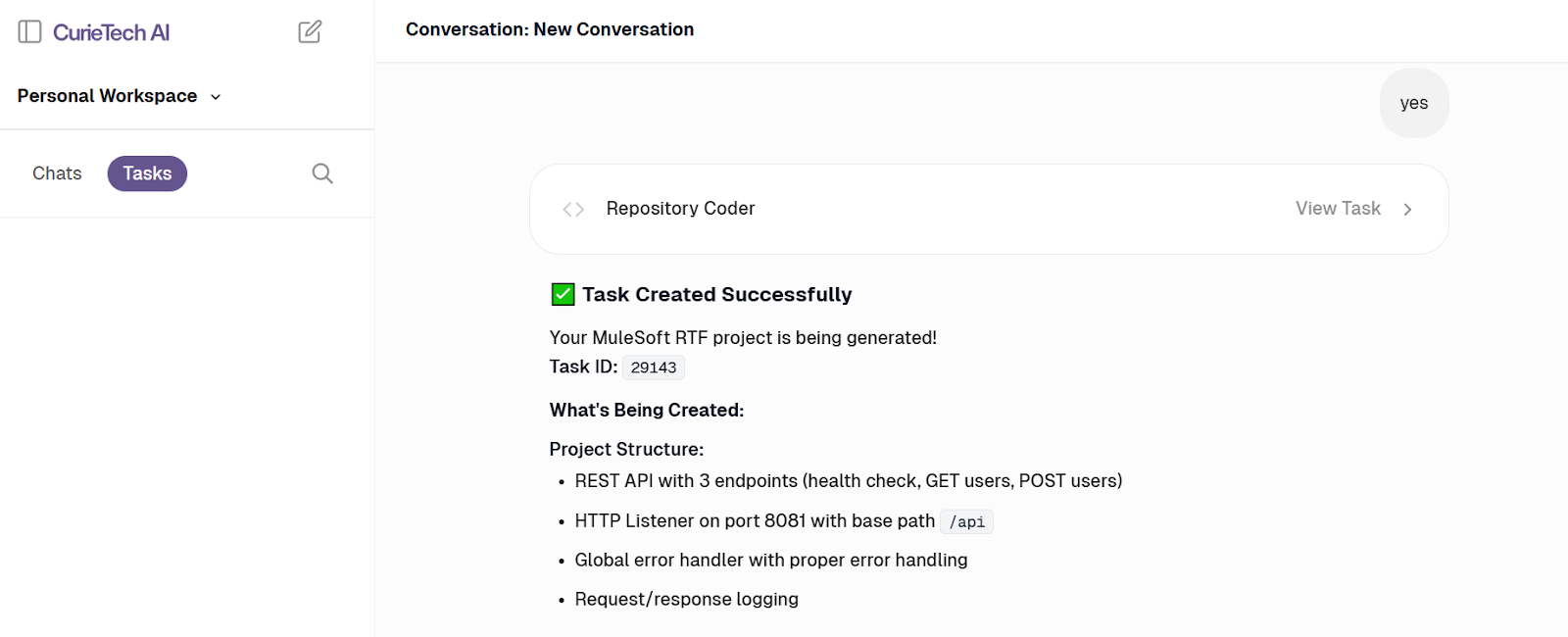

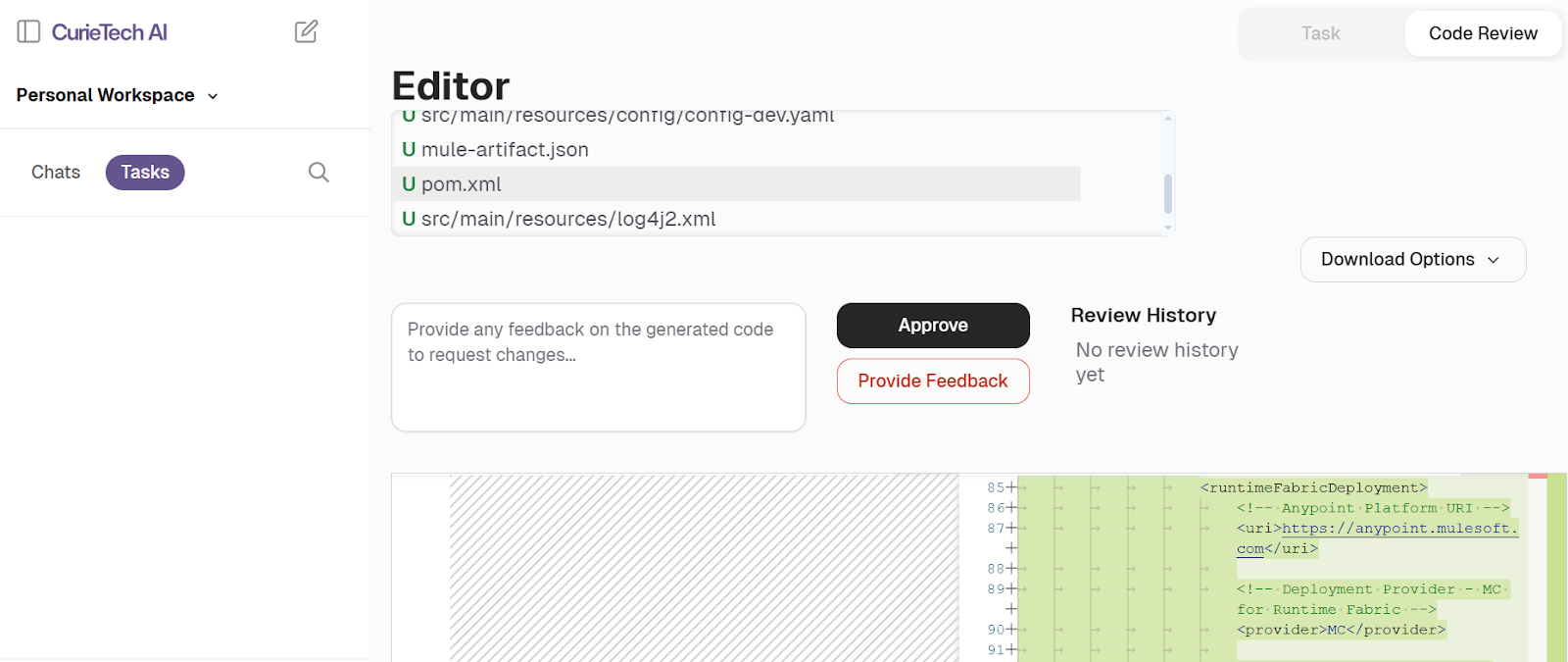
The corresponding RTF deployment configuration in the POM.xml file is automatically generated as follows:
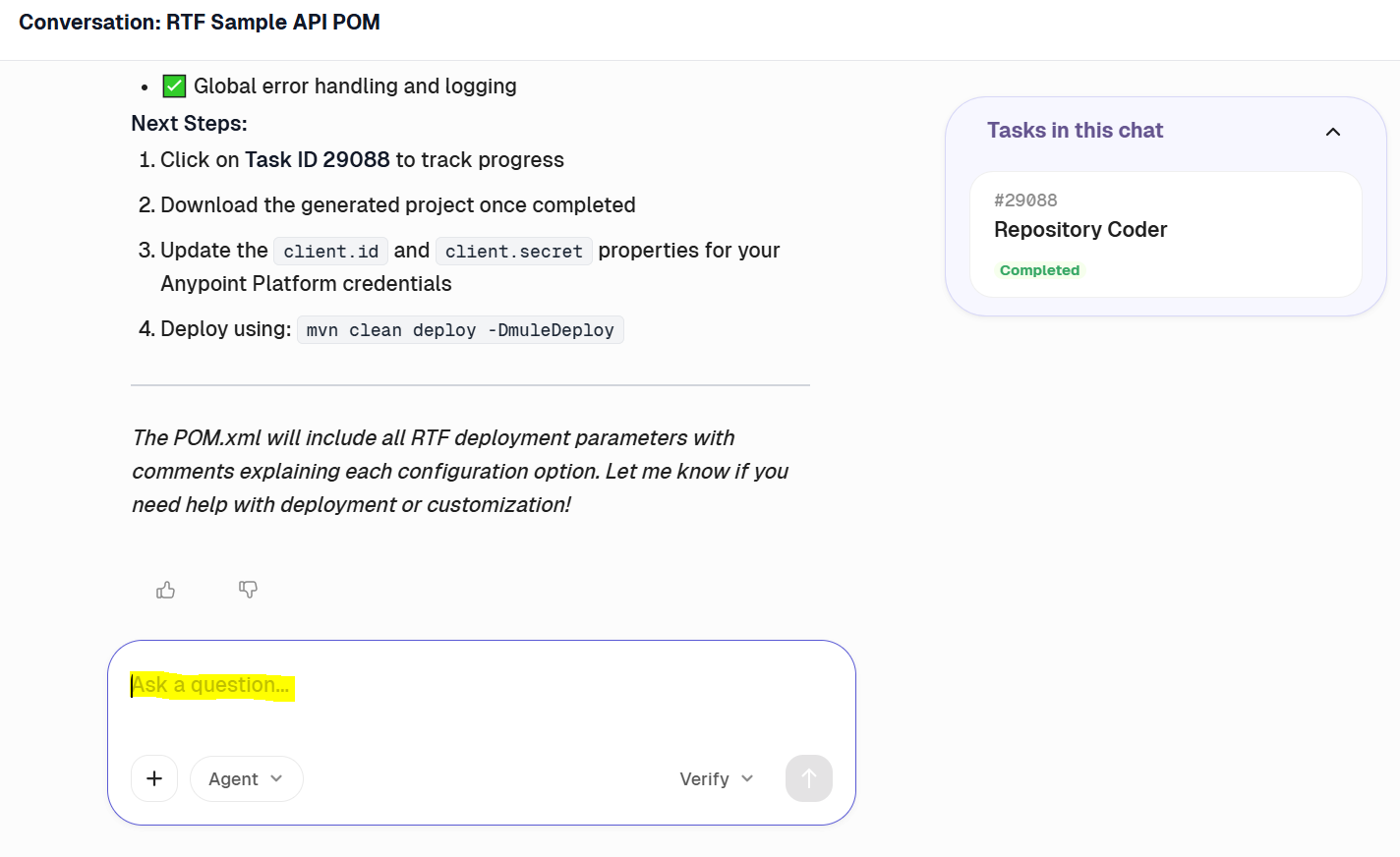
CurieTech also provides an interactive Q&A chat that supports teams in understanding RTF deployment configurations during project setup, as shown below:
Choosing the right RTF deployment model
Runtime Fabric supports multiple deployment models, enabling organizations to run Mule applications in environments that align with their infrastructure strategy, operational maturity, and compliance requirements. Rather than enforcing a single hosting approach, RTF integrates with different Kubernetes-based setups while maintaining consistent application governance through Anypoint Platform.
The choice of deployment model typically depends on factors such as existing Kubernetes investments, control requirements, security policies, and the level of operational responsibility an organization is prepared to manage.

The following table compares RTF deployment models across infrastructure control, operational effort, scalability considerations, and compliance alignment.
Each deployment model addresses different operational and compliance requirements, making the selection largely dependent on an organization’s infrastructure ownership model, governance needs, and tolerance for operational responsibility.
Best practices for RTF operations
Operating MuleSoft Runtime Fabric effectively requires a disciplined operational approach that balances Kubernetes fundamentals with platform-level governance. The following practices focus on improving reliability, security, and operational consistency while maintaining predictable day-to-day management as deployments scale:
- Use managed Kubernetes where possible: When supported by organizational policies, deploying Runtime Fabric on managed Kubernetes services such as Amazon EKS, Azure AKS, or Google GKE can significantly reduce operational overhead. These platforms handle core cluster responsibilities—including control plane availability, node lifecycle management, and patching—allowing teams to focus on deploying and operating Mule applications rather than maintaining Kubernetes infrastructure.
- Define explicit resource allocations: Mule applications running on Runtime Fabric should always be deployed with clearly defined CPU, memory, and vCore allocations. Explicit resource settings help ensure predictable application behavior and make capacity planning more reliable across the cluster. This practice becomes increasingly important as the number of applications and replicas grows.
- Isolate environments using namespaces: Kubernetes namespaces provide a clean, effective way to separate development, testing, and production workloads within a Kubernetes cluster. Apparent isolation reduces the risk of accidental cross-environment impact, improves security boundaries, and simplifies operational management across different lifecycle stages.
- Secure ingress traffic consistently: Ingress configuration is critical to securing APIs deployed on Runtime Fabric. TLS termination should be enforced at the ingress controller, with mutual TLS applied for sensitive or partner-facing APIs. Additional protections, such as Web Application Firewalls (WAFs) and IP allowlists, can further strengthen the security posture at the network edge.
- Apply Anypoint API policies centrally: API security and governance should be managed consistently through Anypoint API Manager. Applying policies such as OAuth 2.0, client ID enforcement, and rate limiting at the platform level ensures uniform enforcement across all Runtime Fabric–deployed APIs, regardless of where or how they are hosted.
- Use the Persistence Gateway for stateful integrations: Applications that rely on Object Store v2 or persistent VM queues should be configured to use it. This ensures that the state is preserved across pod restarts, scaling events, and node failures, supporting the reliable execution of stateful integration patterns.
- Plan for backup and disaster recovery: Persistent volumes used by Runtime Fabric workloads should be backed up regularly, and restore procedures should be tested periodically to ensure seamless recovery in the event of a failure. This practice is crucial for minimizing data loss and ensuring business continuity in the event of infrastructure failures or recovery scenarios.
- Design clusters for scalability and resilience: Runtime Fabric clusters should be designed with high availability and scalability as baseline requirements. A minimum of 3 controller nodes is recommended to establish quorum and maintain control-plane stability. Worker nodes should be sized based on expected workload characteristics, including concurrency, memory usage, and throughput. Where supported, distributing nodes across availability zones further improves fault tolerance.
- Align Java versions with supported RTF runtimes: Mule applications deployed on Runtime Fabric must use Java versions supported by the selected Mule runtime. At the time of writing, Runtime Fabric supports Mule runtimes running on Java 17. Applications should be compiled, tested, and validated against this version to avoid runtime incompatibilities. Ensuring Java version alignment during development and CI/CD builds helps prevent deployment failures and unexpected behavior in RTF environments.
- Introduce AI-assisted operational support carefully: AI-assisted tools such as CurieTech AI can help standardize configuration generation and reduce repetitive manual work when managing Runtime Fabric deployments. By generating RTF-ready project structures and configuration artifacts aligned with supported deployment models, such tools can support consistency without replacing established CI/CD workflows or operational controls.
{{banner-large-table="/banners"}}
Conclusion
MuleSoft Runtime Fabric (RTF) combines Kubernetes-based orchestration with the governance and management capabilities of the Anypoint Platform. It allows Mule applications to run in containerized environments while maintaining centralized security, policy enforcement, and operational control. RTF supports deployments across managed Kubernetes services, OpenShift, on-premises infrastructure, and hybrid environments, enabling teams to align integration platforms with existing infrastructure and compliance requirements.
As RTF environments scale, automation becomes essential for maintaining consistency and reducing manual effort. Tools that assist in generating and maintaining RTF-ready configurations, such as CurieTech AI, help standardize deployments while integrating with existing CI/CD workflows. Together, these capabilities provide a stable, scalable foundation for running Mule applications in modern container-based environments.