
Anypoint MQ: Tutorial, Examples & Best Practices
MuleSoft is an integration platform facilitating seamless connectivity across applications, systems, and data sources. It leverages integration methods like web services, batch processing, and streaming. One such method is event-driven integration, which is particularly effective for building loosely coupled, scalable, distributed systems.
In such architectures, queueing mechanisms are critical to enabling reliable asynchronous communications. MuleSoft offers Anypoint MQ, a multi-tenant, cloud-based message broker that allows the decoupling of services and increases fault tolerance by controlling the load on consuming services. Queues also act as buffers, ensuring message delivery when downstream systems are unavailable.
This article covers different aspects of messaging with Anypoint MQ, from introduction to setting up end-to-end integrations.
Summary of key Anypoint MQ concepts
Introduction to Anypoint MQ
Anypoint MQ is a queuing service fully integrated with the Anypoint Platform for synchronously exchanging data among different applications. It acts as a complete solution for asynchronous messaging, providing the following features:
- Queues and message exchanges: Anypoint MQ works on the widely adopted queuing mechanism, where you can send messages to queues and pull from them. It also provides support for message exchanges, which can be utilized to bind queues and route messages according to defined rules.
- Management console and usage information: The Anypoint Platform provides a management console for monitoring queues, manually purging data messages, checking in-flight messages, and more. The Access Management page offers complete usage information, including the number of messages and API requests.
- Disaster recovery: MuleSoft ensures messages are delivered even if services go down temporarily. Each region has Anypoint MQ services deployed in multiple availability zones (AZs), so even if one of the availability zones goes down, the other availability zone can continue serving requests. It also allows for the creation of fallback queues in an entirely different fallback region, ensuring no service interruption even if all availability zones go down in an area.
- REST APIs for non-Mule applications: Anypoint MQ also provides out-of-the-box APIs to manage and interact with queues in the Anypoint platform using the HTTP protocol. This can be useful for communicating with non-Mule applications to send and retrieve messages from queues, create queues and message routing rules, retrieve queue information, and even retrieve statistics and metrics for queues and message exchanges.
Benefits of using queues
Queues offer essential benefits in distributed systems, enabling applications and services to communicate asynchronously, scale independently, and recover from failures. Here are some of the key benefits:
- Decoupling: Queues allow producer and consumer decoupling, making it simple for applications to scale and be maintained independently.
- Load buffering: Queues help absorb traffic spikes by buffering load and acting as temporary storage for in-flight messages, allowing consumers to operate according to the capacity of available resources.
- Reliability: Queues can also add reliability to flows through message persistence and retry mechanisms. When a message is pushed to a durable queue, it can be stored until the consumer successfully processes it.
- Fault tolerance: Queues allow recovery from failures without data loss. If the consumer fails to process the message or is temporarily unavailable, the message can be retried later from the queue, ensuring continuity. This method guarantees that messages are not lost during intermittent application failures or network issues.
Comparing Anypoint MQ with VM queues and other queueing mechanisms
VM queues are intra-app in-memory queues that work in the same Mule runtime, enabling lightweight asynchronous communications between modules/flows in the same application. Anypoint MQ, on the other hand, supports persistent, cross-app communication, allowing the decoupling of services across CloudHub apps with RESTful access to external systems. It also provides high availability and cloud-native features.
Other queueing mechanisms, such as Apache Kafka, RabbitMQ, or AWS SQS, are platform-agnostic and designed for enterprise-scale, event-driven architectures. These solutions offer advanced features like pub/sub, streaming, or complex routing but require additional setup, infrastructure, and management outside the MuleSoft ecosystem.
{{banner-large-graph="/banners"}}
Understanding messaging in Anypoint MQ
Messaging in Anypoint MQ follows the principles of asynchronous communication, enabling non-blocking, event-driven communication across applications. To better understand the core concepts, let's explore the following key components in detail.
Queues and message exchanges
Queues in Anypoint MQ are used for point-to-point asynchronous communication. Messages are published to a queue from a producer client, and another client, called a subscriber, consumes them. Queues act as temporary storage for messages until a consumer consumes them.
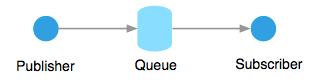
Anypoint MQ supports two types of queues:
- Standard queues: These are built for processing messages quickly; they do not guarantee the order of message processing, but they guarantee message delivery at least once.
- FIFO queues: FIFO queues guarantee the order of message processing. They are optimal for scenarios where the order of messages is strictly essential, while speed is less critical. They also guarantee message delivery exactly once.
Message exchanges act as routing agents that receive messages from producers and distribute them to one or more bound queues based on the binding key. A binding key represents a relationship between the message exchange and the queue, which tells the exchange where to deliver a message.
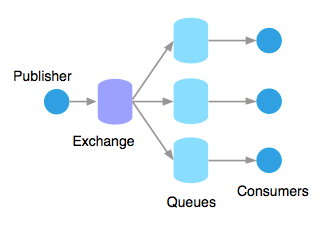
For example, when a hotel booking is made on a travel platform, multiple downstream actions may be triggered, such as SMS confirmation for the user, email receipt, and updating their booking predictions. This can be achieved using message exchange, where three separate queues are bound to the exchange: SMS Notification, Email, and Prediction services. As soon as a booking event is published to the exchange, all queues receive a copy of the message, enabling parallel and decoupled processing by their respective consumers.
Messaging patterns
Messaging patterns define how messages are transmitted and consumed across systems. Anypoint MQ supports several key patterns that enable scalable, reliable, and fault-tolerant communications:
- Publish-subscribe: The publish-subscribe pattern enables communication between a producer and multiple subscribers. Once the producer publishes a message, consumers who want to receive it can subscribe to the predefined channel to process the message. This pattern can be used when multiple actions need to be performed per event; the hotel booking example discussed above in this article is an example.
- Competing consumers: The competing consumers pattern is familiar and works well for distributing processing across multiple workers. Each queue can have multiple consumers, but only one gets and processes the message. This pattern can reduce the load on one particular worker and distribute processing, handling traffic spikes in high-volume times. It’s also easy to scale because more workers can be added per load
- FIFO messaging: FIFO messaging works on the first-in, first-out principle. The queues preserve the order of message delivery and processing. The first message is processed, and the other messages can be consumed in order. This pattern should be used when maintaining the order of messages, which is of the utmost importance, for example, in critical workflows like transaction systems.
- Dead letter queues and redelivery: Dead letter queues store messages that have failed multiple times and have passed the maximum threshold of retries. They allow for analysis of the failure and manual reprocessing at a later time. These queues act as a fail-proof mechanism to avoid infinite retries of messages and prevent faulty messages from blocking valid ones.
Setting up Anypoint MQ
To start leveraging Anypoint MQ for event-driven messaging, configure queues and create a connected app to connect from external systems. Here is a step-by-step guide to help you set up Anypoint MQ and connect your applications.
Creating a queue
First, you need to create a queue that will be used to send and receive messages. Here are the steps for creating a queue in Anypoint Platform:
- Sign in and navigate to Anypoint MQ -> Destinations.
- Select the type of queue that you need to create: standard or FIFO.
- Enter the queue name and provide other details, such as the following:
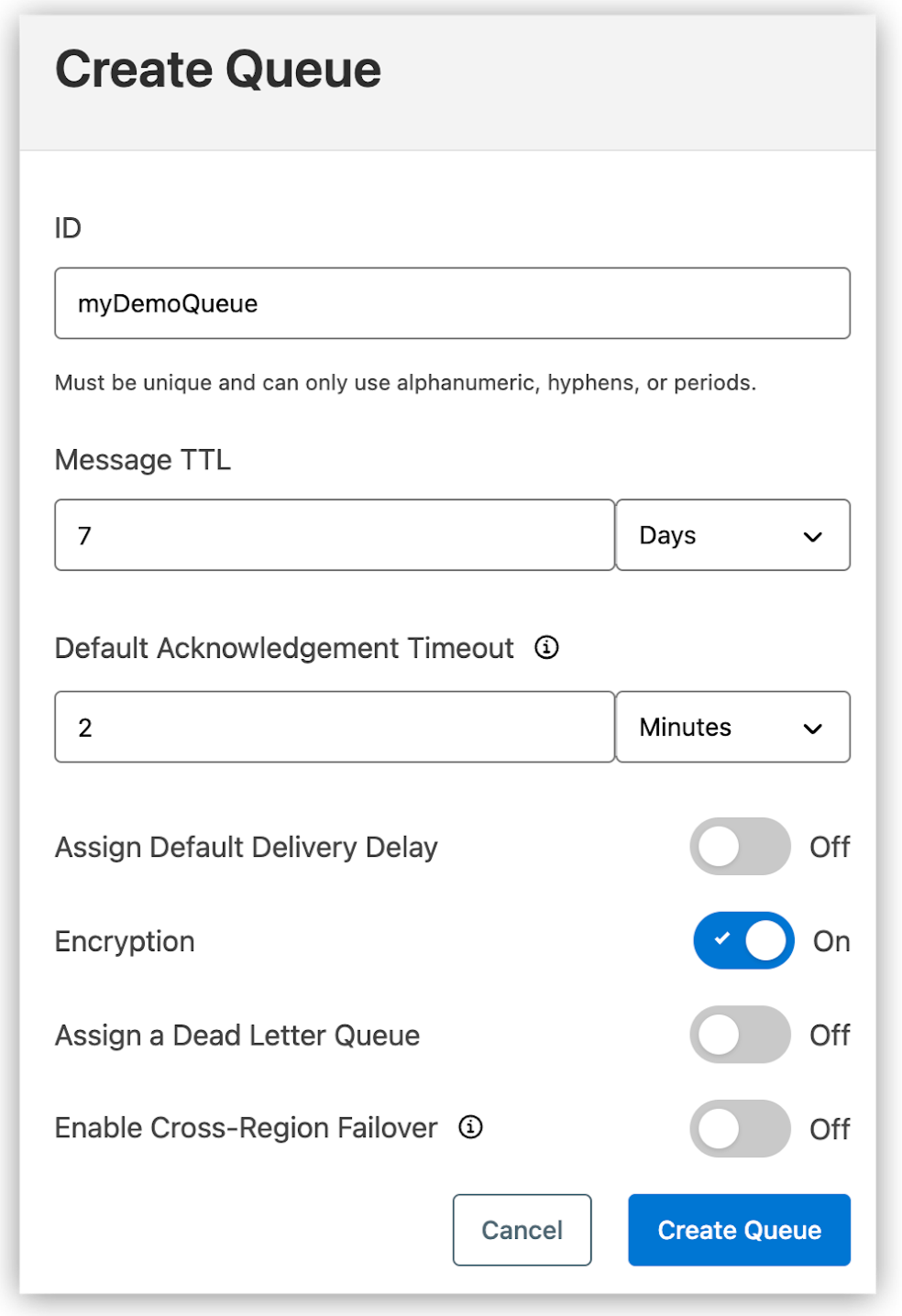
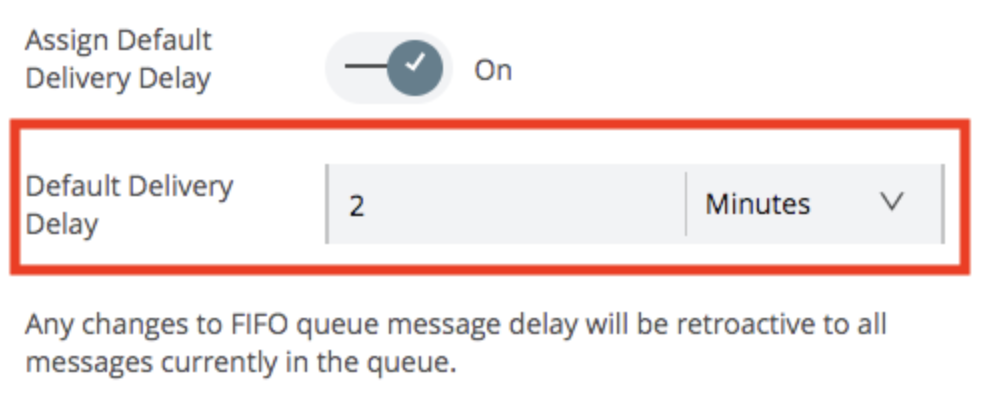
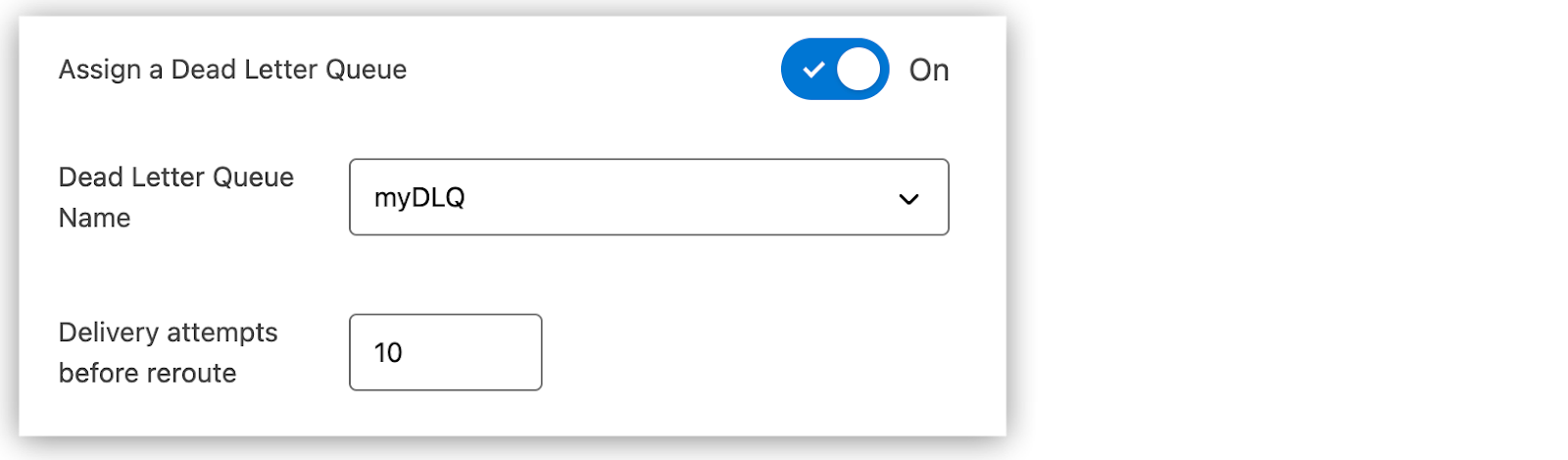
- Click on the Create Queue button to finish creating the queue. This should make the queue on the platform, and it will now be available to interact with.
Creating the connected app
To connect to an Anypoint MQ queue, you must create a connected app that your MuleSoft application can utilize. Here is the step-by-step process to make a connection with the correct permissions to interact with MQ:
- Navigate to Access Management -> Connected App -> New Connected App. Add the Administer destinations scope, which provides the necessary permission to perform MQ operations.
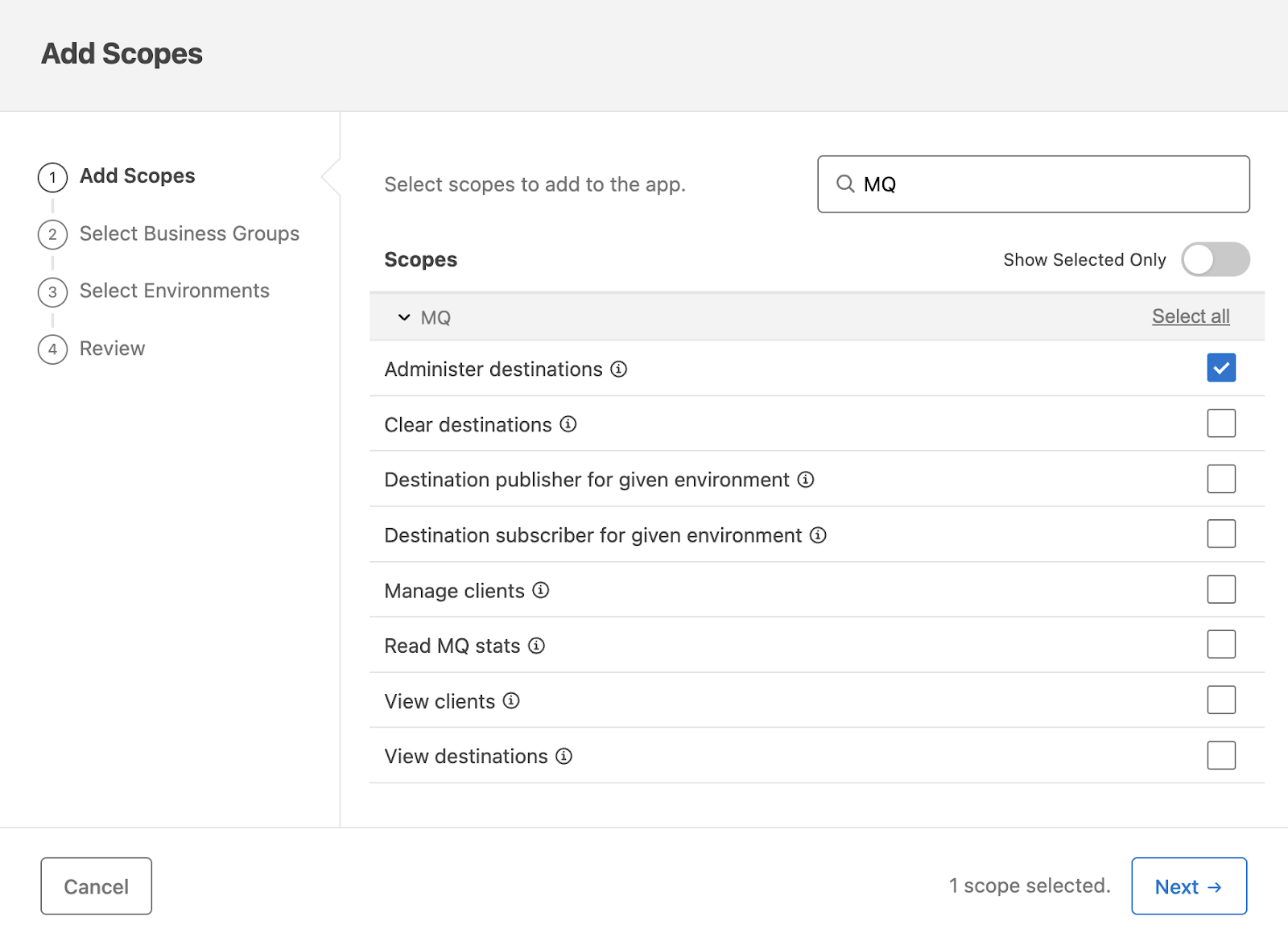
- Hit Next and select the business group for the connected app and the environments this connected app should access. Review the configuration and click on Finish.
- Your connected app should now be available to use. Copy the app's client ID and secret to connect to Anypoint MQ from the Mule application.
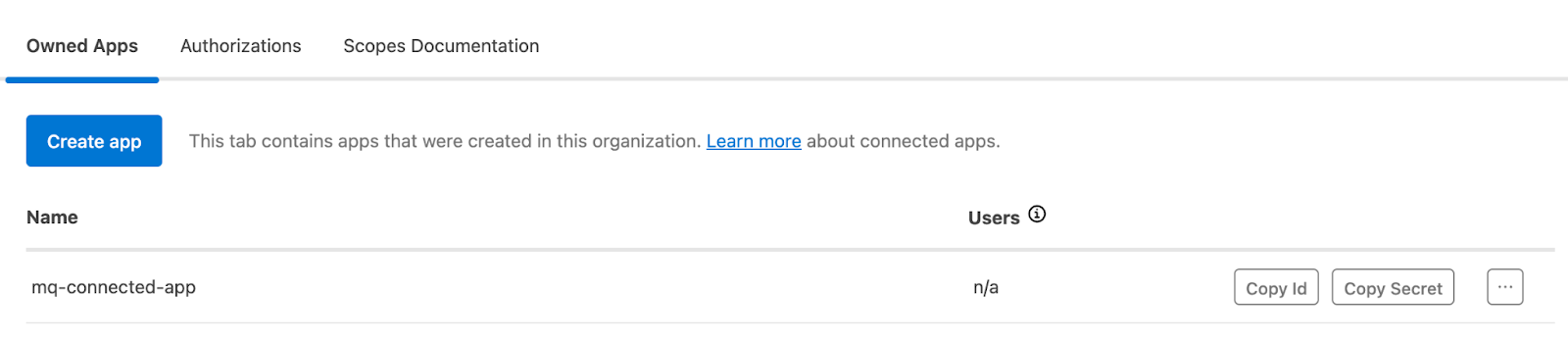
You can also use CurieTech’s Single Repo Code Lens tool to configure Anypoint MQ and easily get guided assistance during setup. CurieTech AI is a specialized platform built for MuleSoft that provides a suite of agents that help you create, enhance, document, and review end-to-end production-ready integrations using natural language prompts. These tools reduce development time and effort while maintaining code standards and handling edge cases.
Here is an example using the Single Repo Code Lens, which uses a simple prompt to help understand how Anypoint MQ setup can be done on both the platform and application sides.
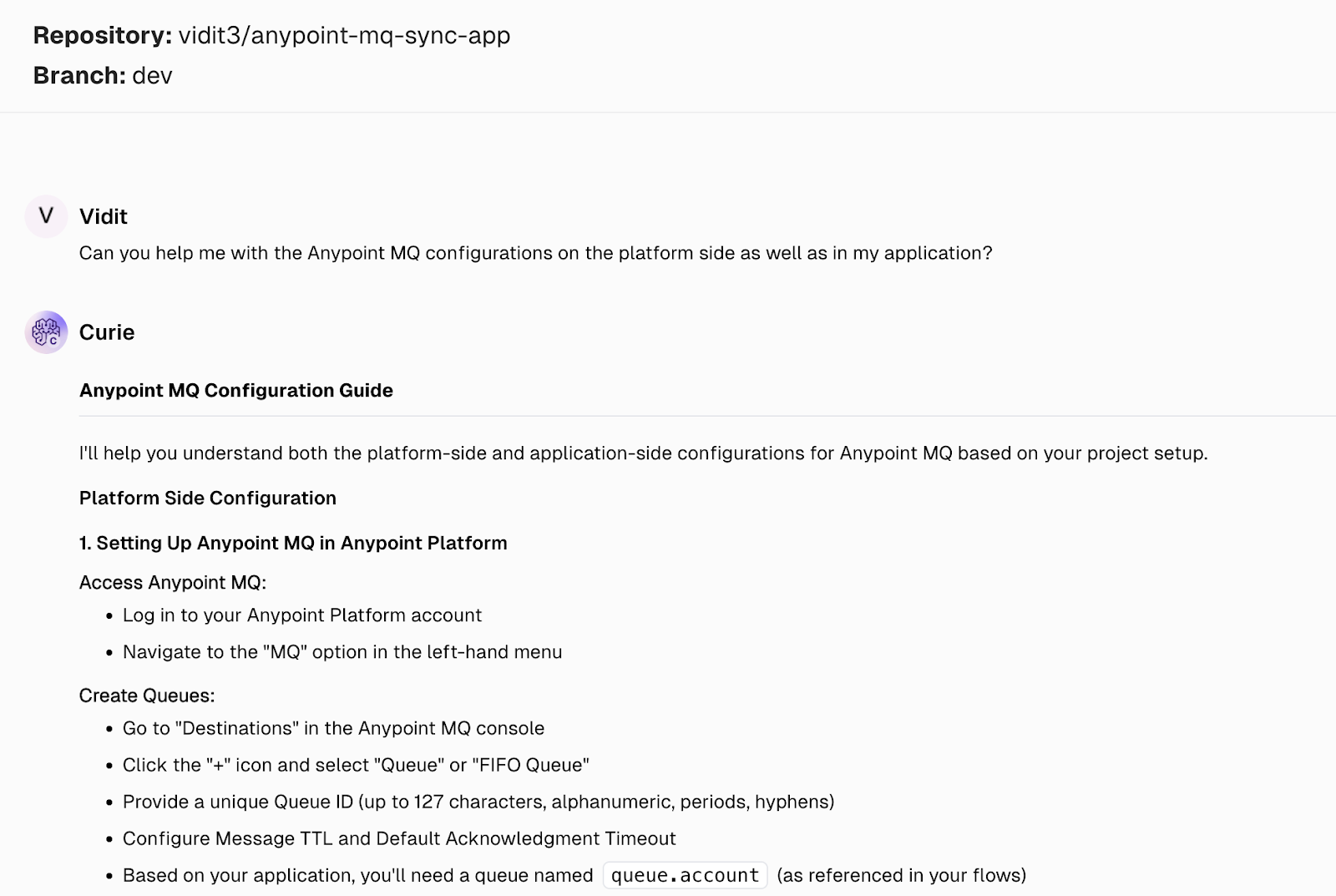
The tool provides step-by-step feedback based on the question, code snippets, a checklist, best practices, and additional recommendations for developing a robust integration.

Integrating Anypoint MQ into a Mule application
Let's look at how to utilize the queues in a Mule application to build a simple asynchronous application. This example has two simple flows:
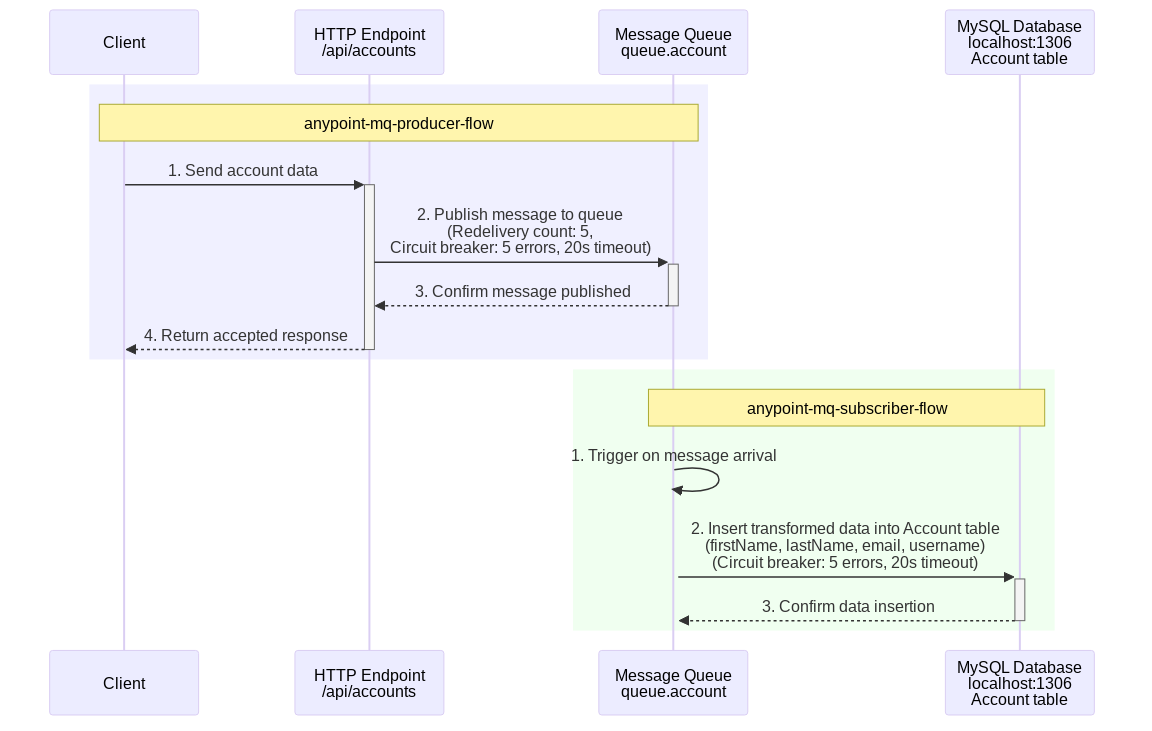
- Producer: An asynchronous flow with an HTTP listener that accepts requests to create an account and posts the message to an Anypoint MQ queue called queue.account for further processing. After publishing the message, it returns a 202 Accepted response.
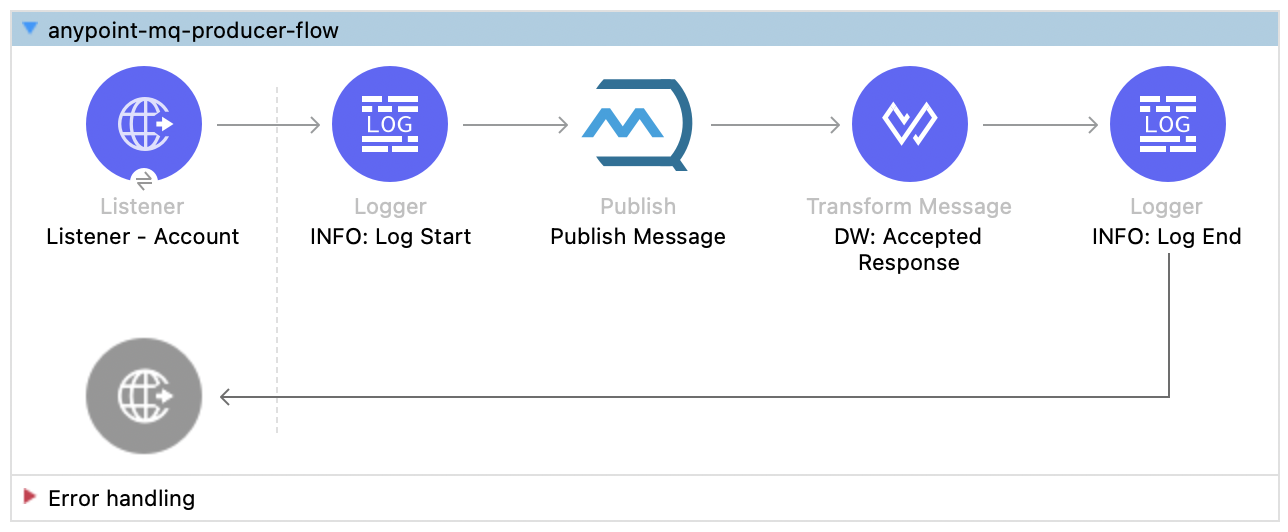
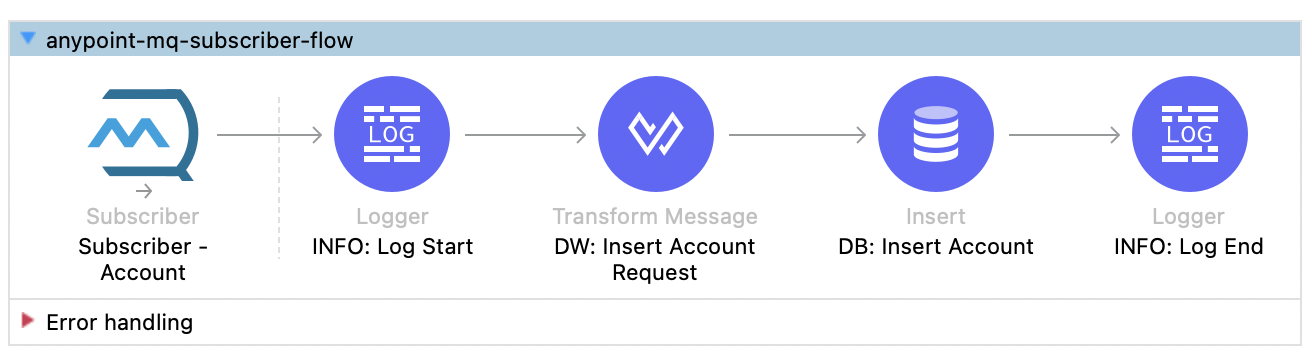
- Subscriber: A second flow subscribes to messages from the queue.account and inserts the record into the account table in the database.
Here is the detailed step-by-step process for publishing and subscribing to a message using Anypoint MQ:
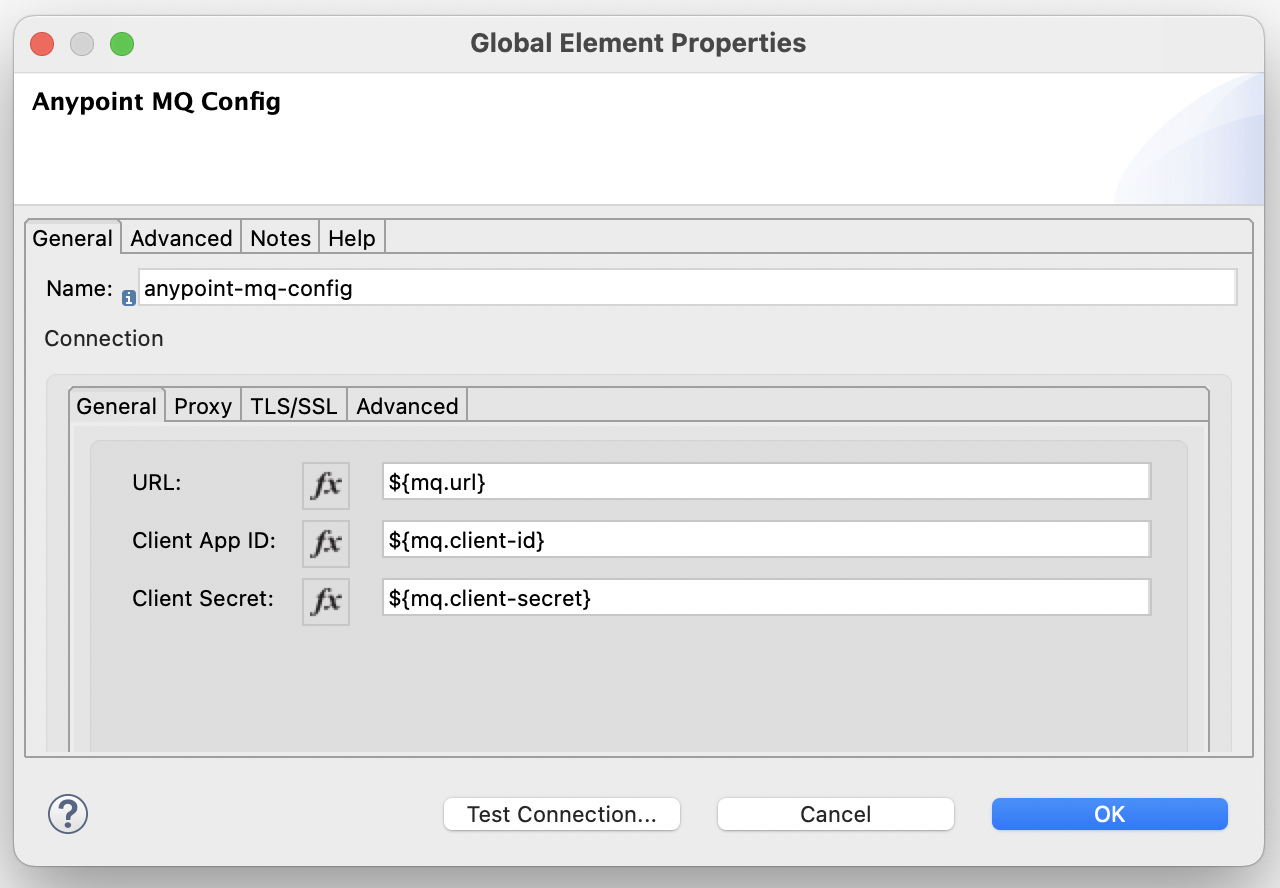
- To connect to Anypoint MQ, create a new Anypoint MQ config and enter the details: URL, client app ID, and client secret.
- Create a flow that uses an HTTP listener to receive requests to create an account in a database. This flow publishes a message to a queue in Anypoint Platform using the Anypoint MQ: Publish operation. Here is a code snippet of the operation that publishes the message to the queue.account.
<anypoint-mq:publish doc:name="Publish Message" doc:id="d35db57b-67f3-4b20-8132-036faf418188" config-ref="anypoint-mq-config" destination="queue.account"/>
- Once the message is published, subscribe to it using the Anypoint MQ: Subscriber operation and set the destination to the queue.account. This operation listens for any new messages published to the subscribed queue. Here, the acknowledgement mode is set to AUTO, which means the Mule runtime automatically handles the acknowledgement of the message based on its success/failure.
To manually ACK or NACK a message, you can set the acknowledgement mode to manual and use the Anypoint MQ: ACK and Anypoint MQ: NACK operations based on your requirements.
Here is the code snippet for the subscriber.
<anypoint-mq:subscriber doc:name="Subscriber - Account" doc:id="fadce893-7c2f-44b6-ba5b-6441981d3f6f" config-ref="anypoint-mq-config" destination="queue.account" acknowledgementMode="AUTO">
- Once the message is received, you can push the data to the database using the DB:INSERT operation. Here is the code snippet for the Database insert operation.
<db:insert doc:name="DB: Insert Account" doc:id="1780ca68-c21f-4cb8-bc35-4b1a1ee03ef3" config-ref="mysql-db-config">
<db:sql >
<![CDATA[INSERT INTO Account VALUES (:firstName, :lastName, :email, :username)]]>
</db:sql>
</db:insert>
- Once both producer and subscriber flows are configured and developed, you can test them by publishing a message to the accounts queue using the HTTP endpoint for the producer. Once the message is published, it should be received by the subscribing flow and inserted into the database.
To simplify the process and further enhance this example, you can leverage the AI capabilities of CurieTech AI’s Repository Coder tool. Let's explore how to use CurieTech AI's Repository Coder to generate the producer and subscriber flows used in the example above. Sign up at CurieTech AI and navigate to the Repository Coder tool. Then provide your step-by-step prompt to generate the flows. Here is the prompt used as part of this example:
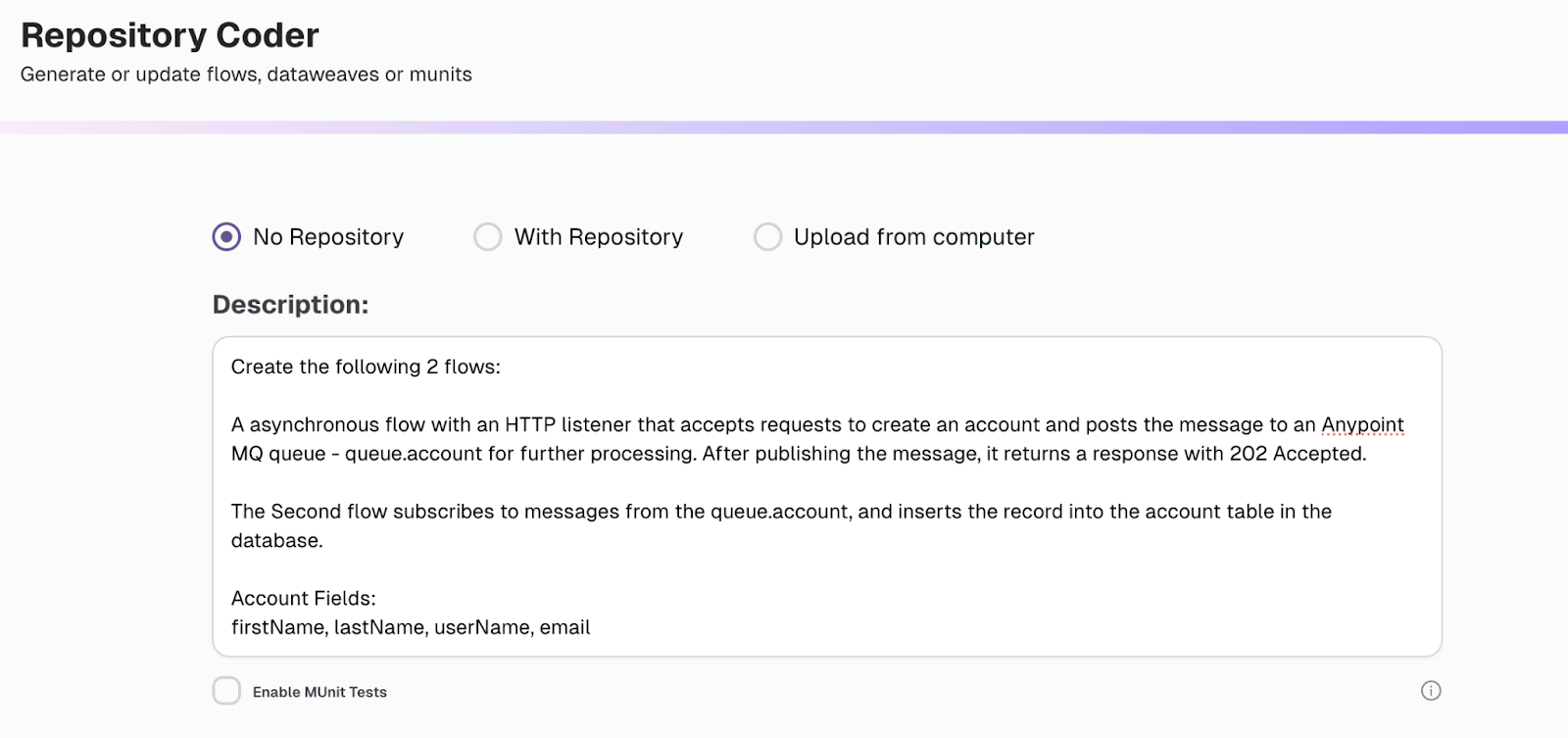
Once the task is submitted, the repository coder tool generates the end-to-end complete flows with all configurations and error handling. Here is a snapshot of the task from the tool after completion.
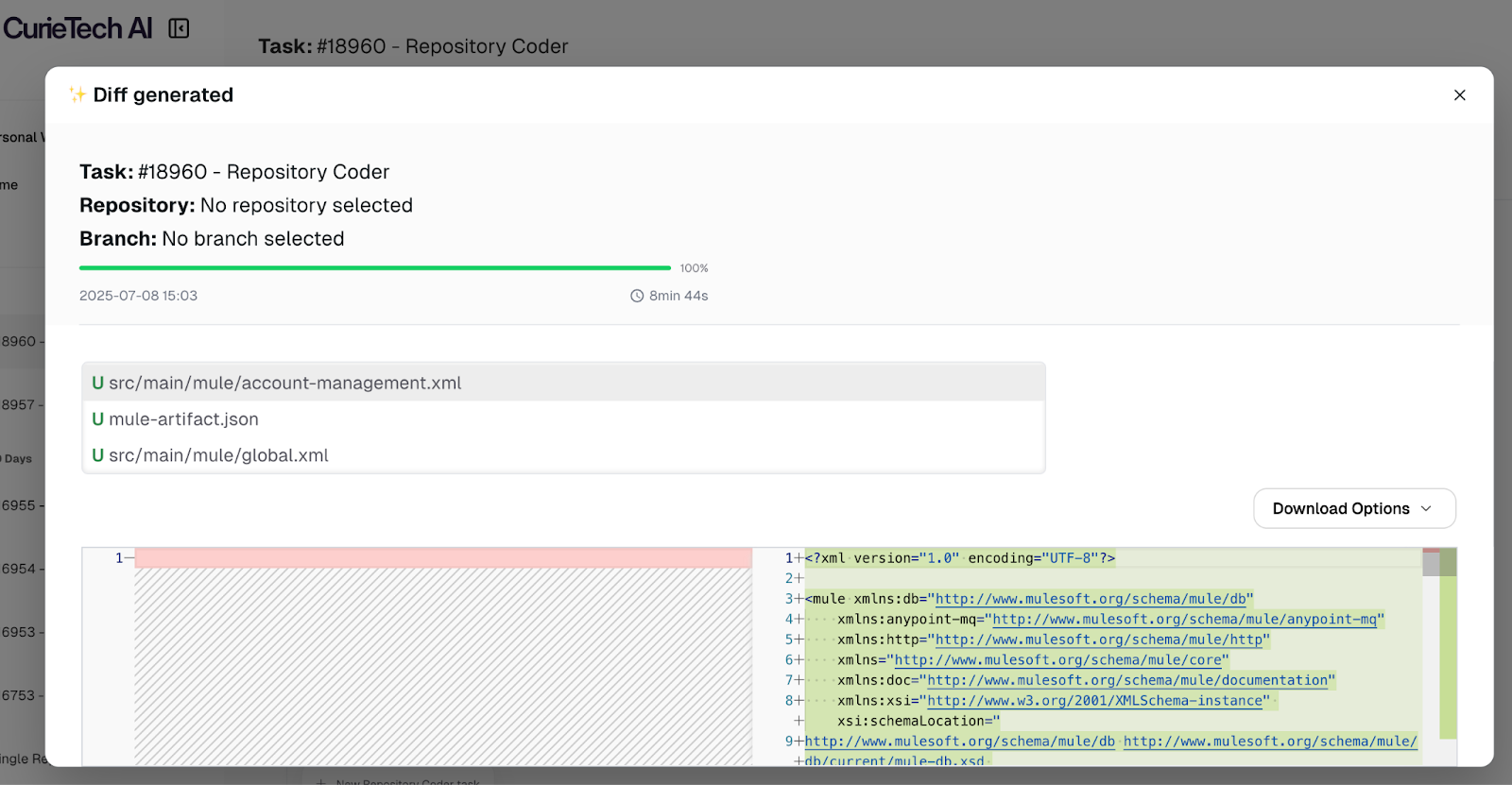
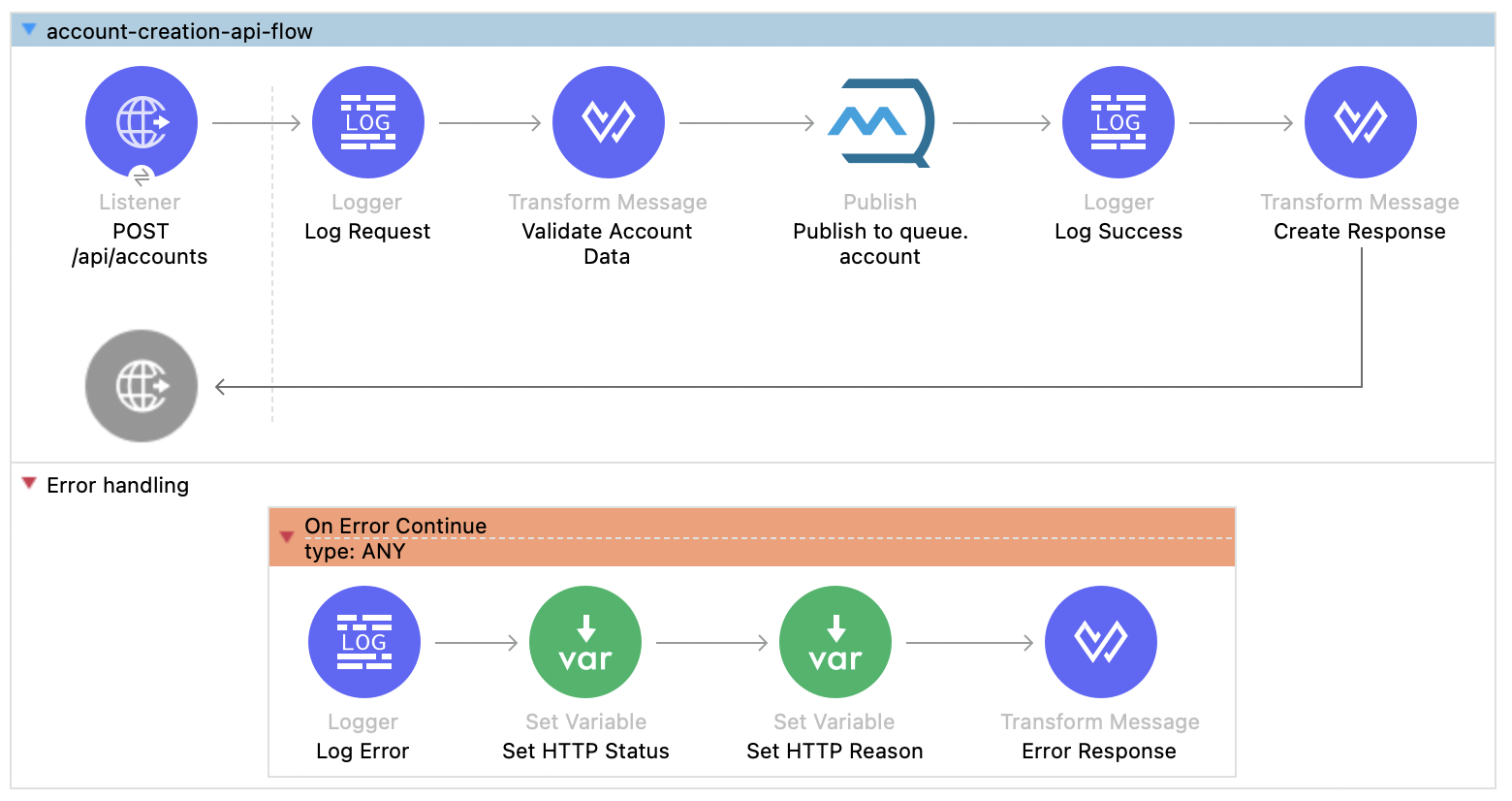
Here is how the flows look after being imported into Anypoint Studio. The created producer flow works exactly as described in the prompt. It listens to account creation requests on an HTTP endpoint, validates them, and publishes the message to the account queue.
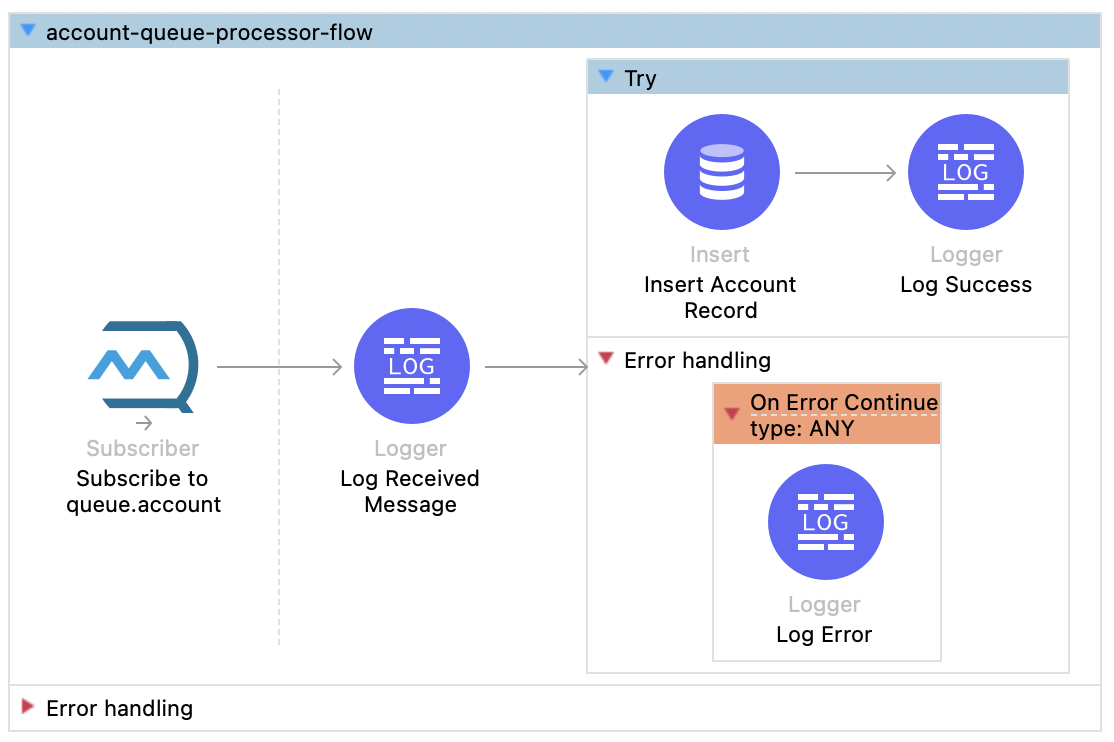
The subscriber flow listens to any messages on the accounts queue and inserts them into the database.
{{banner-large="/banners"}}
Decoupling retail order processing: A real-world use case
In today’s fast-paced digital commerce ecosystem, retail platforms must handle high volumes of customer transactions while ensuring system reliability, scalability, and maintainability. Mulesoft’s Anypoint MQ can provide a robust solution for building asynchronous, event-driven architectures.
Consider a large retail company like Amazon, where the customer experience involves multiple interconnected systems, from placing an order on the platform to receiving the delivery. At a high level, there are various services involved:
- Order management
- Inventory management
- Payment gateway
- Shipping provider service
- Customer notification service
Message flow architecture utilizing Anypoint MQ capabilities
The message flow would follow this sequence:
- Order submission: The front-end application sends the order to the Order API, which validates and publishes the message to an order queue: queue.order.
- Inventory processing: A service subscribes to the queue.order, checks item availability, and reserves stock. Once it succeeds, it publishes a message to the payment queue, queue.payment.
- Payment processing: The payment service consumes the message from the queue.payment and processes the payment using a third-party payment gateway. If the transaction is successful, it posts a message to the shipment queue.
- Shipment processing: The shipment service consumes the message from the queue.shipment, and books a delivery with the logistics partner. Once confirmed, the message is forwarded to a notification topic exchange, to which multiple notification queues are bound.
- Notification processing: Multiple notification services, such as SMS and email, consume the message from the notification topic and dispatch the order confirmation via the notification channels.
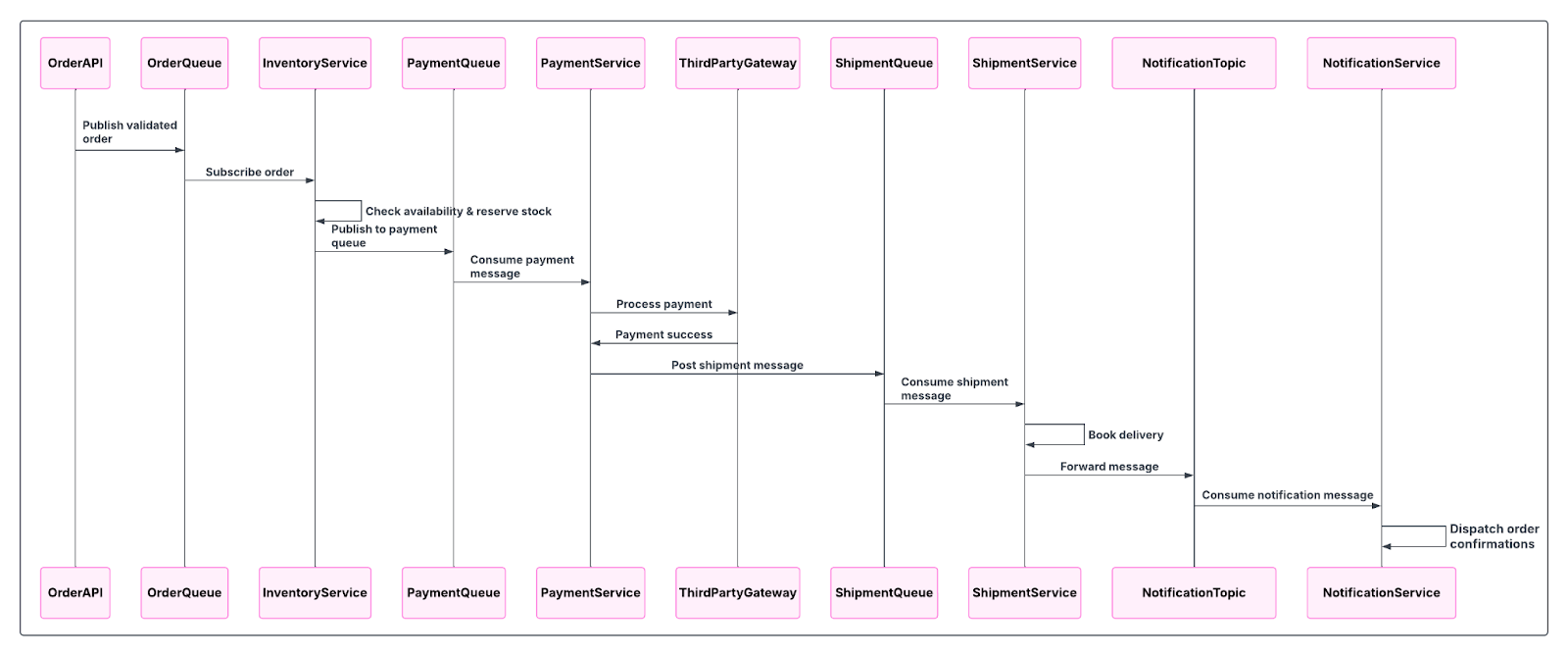
Order Processing Flow Design
This architecture supports the independent processing of messages through isolated services, which can be scaled as needed. For example, suppose the payment processing service starts experiencing issues due to a sudden high volume of transactions. In that case, you can increase the number of workers for the service and handle the sudden spike. Anypoint MQ not only adds reliability but also increases fault tolerance of the entire system, increasing the success rate of the flow and elevating the customer experience.
Handling reliability: Redelivery, circuit breakers, and dead letter queues
Once the basic setup is completed, it's essential to enable redelivery and dead letter queues to add reliability while processing messages.
Redelivery
Adding redelivery in consumer applications ensures that if a consumer fails to process a message successfully, it is pushed back to the queue for reprocessing.
The redelivery policy generates a message key for each new message received. If the processing flow encounters an error while processing the message, it increments the counter associated with the message and pushes the message for reprocessing. If any message exceeds the configured max redelivery count value, Mule throws a MULE: REDELIVERY_EXHAUSTED error and discards the message from the queue. Each message has an attribute called deliveryCount that indicates the number of delivery attempts for that message.
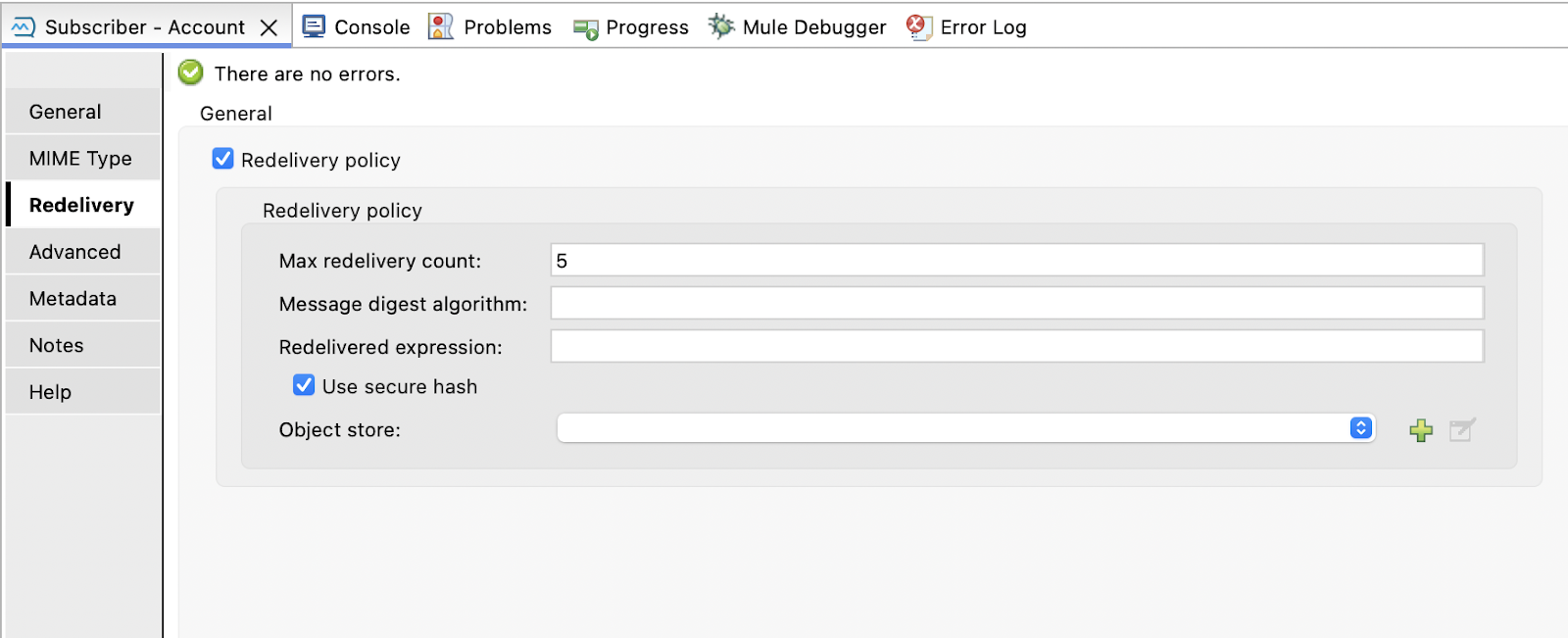
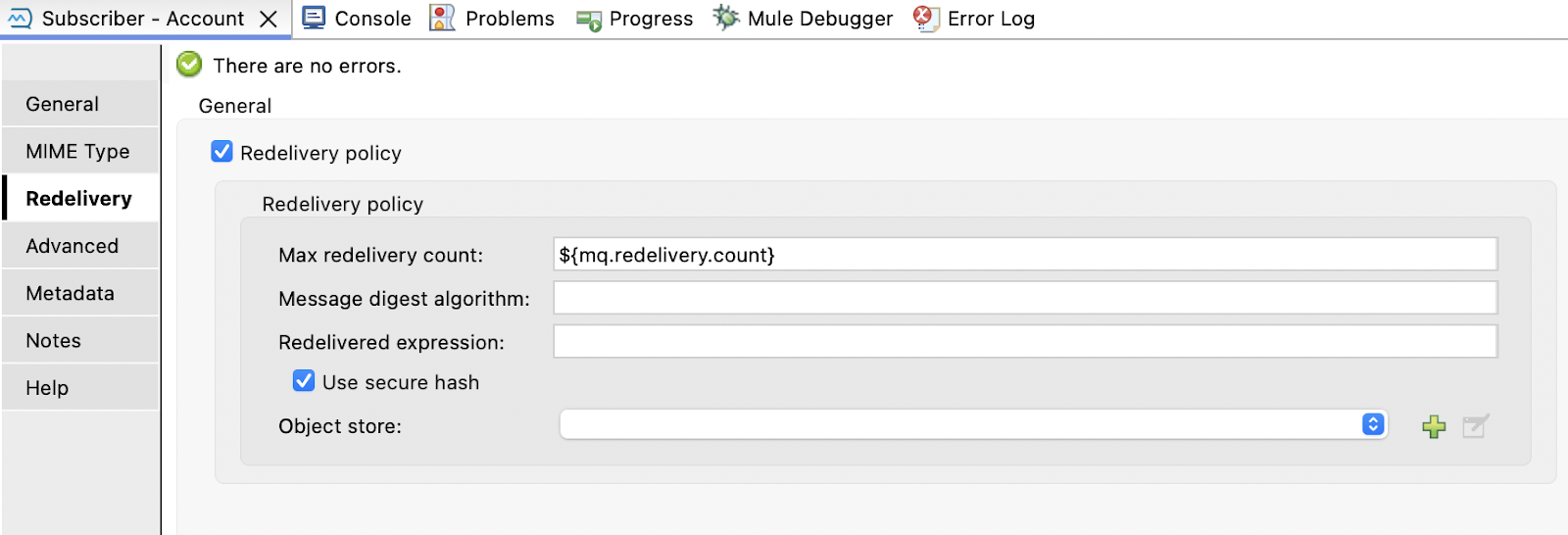
To set up redelivery for an Anypoint MQ subscriber, under the redelivery section, you can configure the parameters to enable redelivery for a message:
- Max redelivery count: This is the maximum number of times a message can be redelivered and processed unsuccessfully before being discarded.
- Message digest algorithm: This is the hashing algorithm for the message; by default, it uses SHA-256.
- Redelivered expression: Defines the expression to determine if the message is redelivered. It can only be used when the Use secure hash option is false.
- Use secure hash: Use only if you are using a secure hash algorithm to identify a redelivered message.
- Object store: This option can set an explicit object store to store message redelivery counters. By default, it uses the default object store in Mule, which has an entry TTL of 300 seconds and an expiration interval of 6 seconds.
Circuit breaker
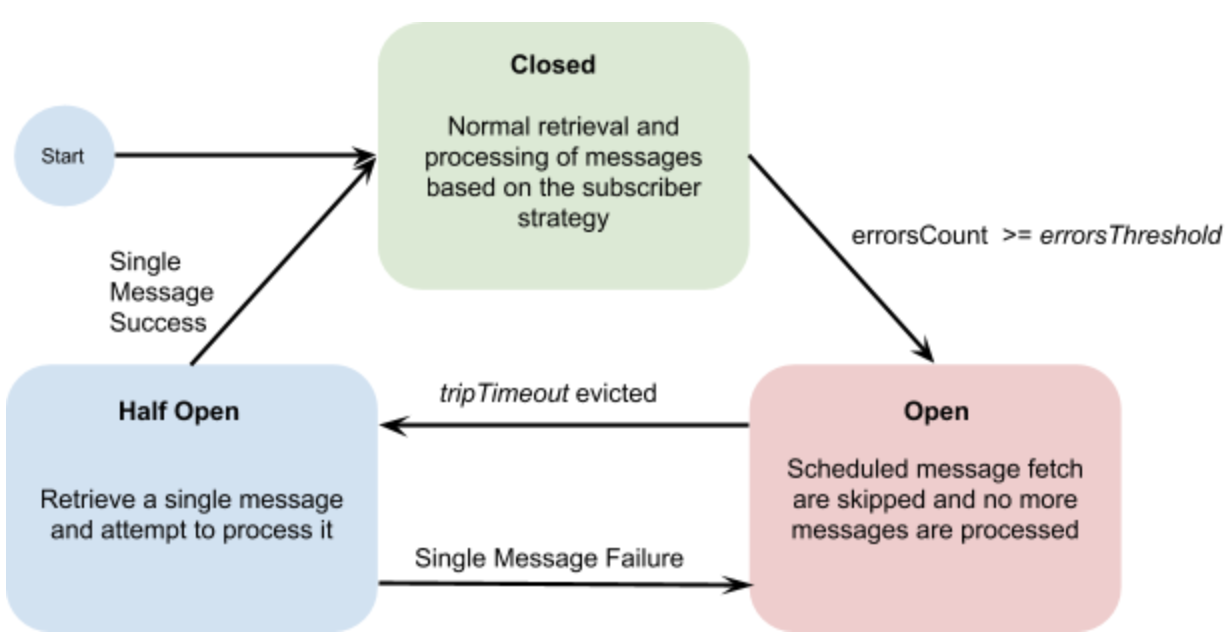
The circuit breaker is a design pattern used in distributed systems that detects repeated failures from downstream services and allows systems to recover gracefully by “breaking the circuit” to avoid overwhelming the underlying services with further requests.
The circuit breaker maintains three states:
- Closed: The normal state; requests flow to underlying services, and failures are tracked.
- Open: After repeated failures, the circuit trips, and no requests are sent for the configured timeout period.
- Half open: Allows a few trial requests to check if the underlying services are back up. If successful, the circuit returns to the Closed state, allowing regular operation; if it fails, it goes back to Open, not allowing any requests to go through.
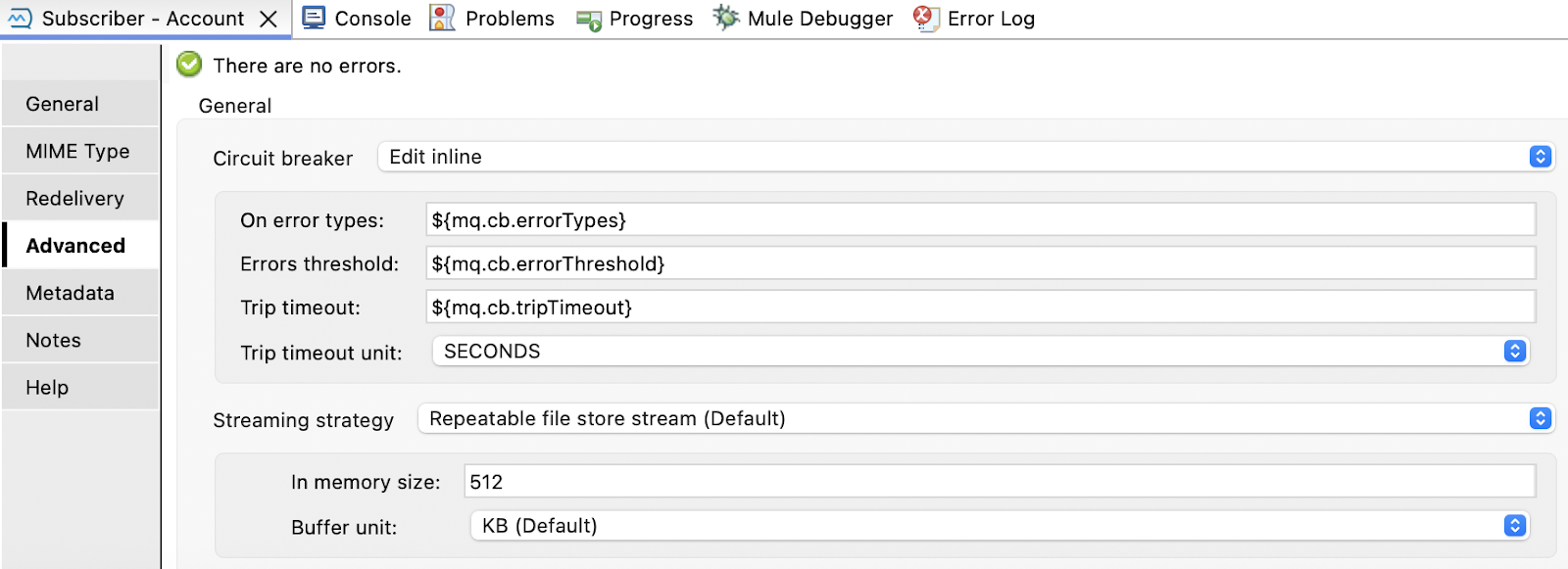
Anypoint MQ has a built-in circuit breaker that can be set up as follows:
- On error types: This field defines which error types will count as a failure in the circuit. Our example flow considers DB: CONNECTIVITY errors, which will count as a failure in the circuit.
- Error threshold: This is the maximum number of errors that can occur before the circuit goes into the Open state.
- Trip timeout: This field specifies how long the circuit remains Open after reaching the error threshold limit.
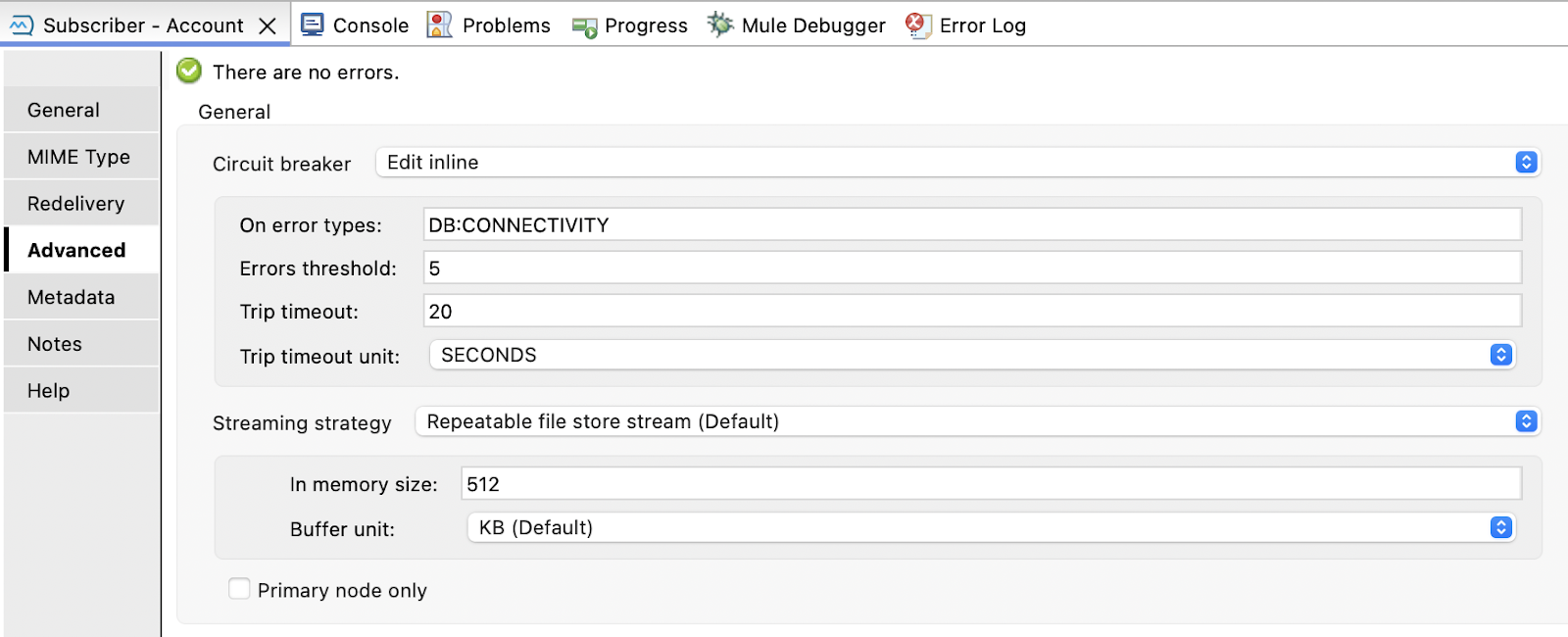
In this example, when the database is unavailable and throws connectivity errors five times, the circuit breaker trips into the Open state, not allowing any requests to flow to the database, thereby allowing the database to recover. After the trip timeout, Anypoint MQ will again allow the requests to flow through (Half Open state), but if the database is still down, the circuit breaker will trip to the Open state again. Once the database comes up, the circuit breaker will return to the Closed state, allowing all requests to go through.
Dead letter queues
Each queue in Anypoint MQ can be assigned a dead letter queue, which can be created as a standard or FIFO queue and assigned to any other queue in the platform in the same region. Once assigned, messages are automatically delivered to the DLQ after exceeding the total delivery attempts, where they can be analyzed for failures and reprocessed manually.
When using DLQs with FIFO queues, it is essential to note that once the message is delivered to a DLQ, the order of messages is not preserved in the FIFO queue as subsequent messages are processed. Therefore, it is recommended not to use DLQs with FIFO queues or, if you do, to use them carefully.
Error handling
Handling errors in Anypoint MQ flows is critical to ensure reliability, proper message processing, and fault tolerance. Effective error handling can minimize application downtime and ensure smooth processing between flows.
Here are some key errors Anypoint MQ can throw, what they indicate, and how to navigate them.
- ANYPOINT-MQ:DESTINATION_NOT_FOUND: This occurs when the destination queue is not present in the organization and environment where the connected app is registered. After processing normal redelivery of the message, these messages can be sent to a DLQ. Once the issue is fixed, try to reprocess the messages again.
- ANYPOINT-MQ:ILLEGAL_BODY: This error can occur when the message being published or consumed is in a format that violates the expected structure. Since these messages need manual intervention before processing, they can be directly sent to DLQ.
- ANYPOINT-MQ:PUBLISHING: This error occurs when the application encounters an error while publishing the message to an Anypoint MQ destination. These messages can be retried with the configured redelivery and circuit breaker config.
- ANYPOINT-MQ:RETRY_EXHAUSTED: This error occurs when a message has exceeded the maximum number of redelivery attempts. These messages can be pushed to the DLQ to learn the reason for the failure and then manually retry.
Here is an example of an acknowledgement mode set to manual. The flow manages the hacking/nacking of the message. This can be done using the ackToken attribute, which is available once the message arrives in the queue. Here is how the complete flow looks.
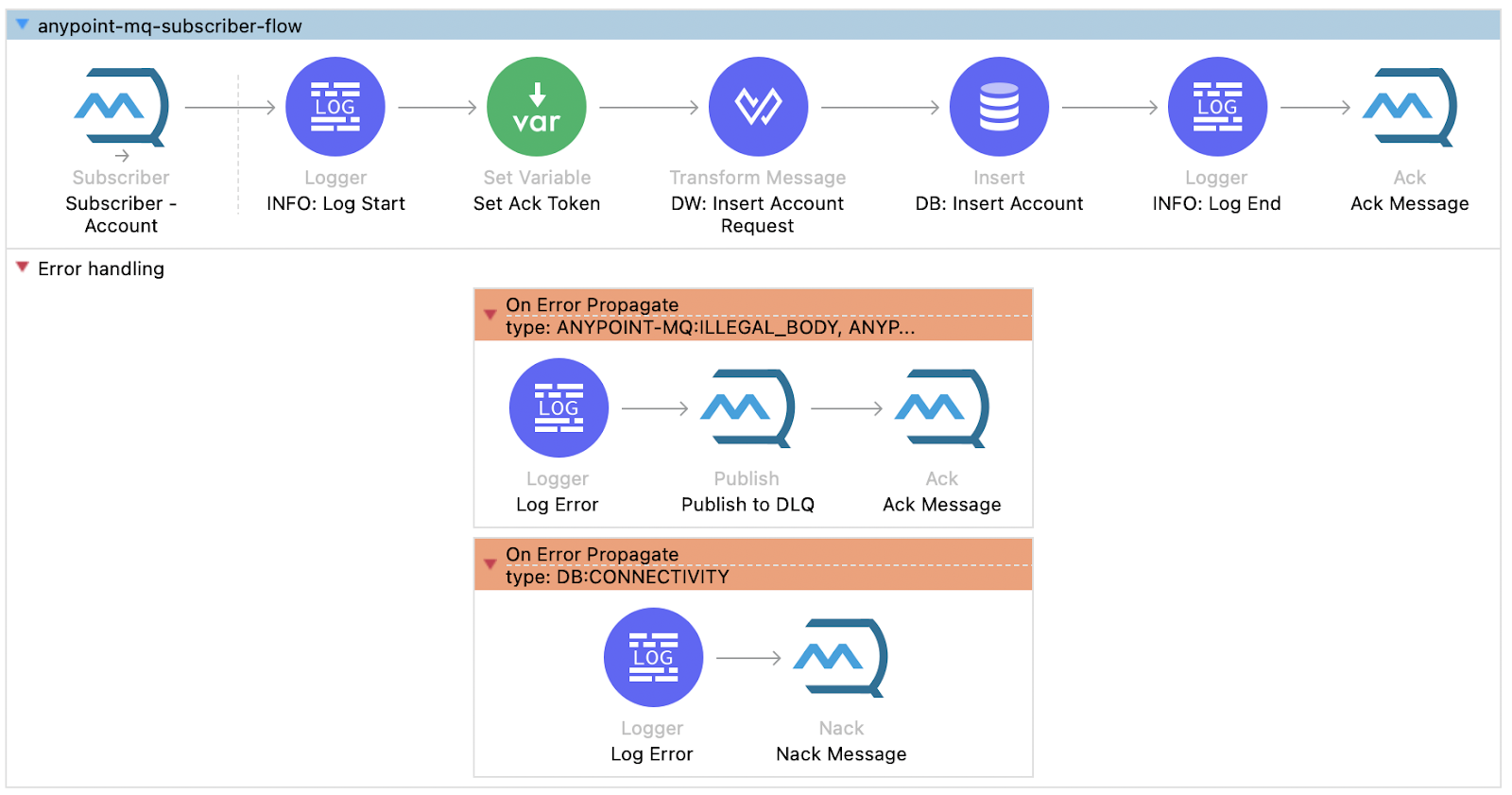
In the successful scenario, the flow acknowledges the message using the ackToken.
<anypoint-mq:ack doc:name="Ack Message" doc:id="71c404e2-e19d-4977-b011-1ef6a92972b3" config-ref="anypoint-mq-config" ackToken="#[vars.ackToken]"/>
In the case of ANYPOINT-MQ: ILLEGAL_BODY, ANYPOINT-MQ: RETRY_EXHAUSTED errors, the message is pushed to a DLQ and acknowledged so it doesn’t get retried.
<on-error-propagate enableNotifications="true" logException="true" doc:name="On Error Propagate" doc:id="46f5d537-6ee7-4ab0-bc89-fa559a426a0d" type="ANYPOINT-MQ:ILLEGAL_BODY, ANYPOINT-MQ:RETRY_EXHAUSTED">
<logger level="INFO" doc:name="Log Error" doc:id="25e1b4af-68ad-4bc7-aaa6-7a32a5f4fe2b" message="Error occurred while processing record:" />
<anypoint-mq:publish doc:name="Publish to DLQ" doc:id="3e137226-b823-471e-b706-a3db998ca29f" config-ref="anypoint-mq-config" destination="dlq.account" />
<anypoint-mq:ack doc:name="Ack Message" doc:id="37230f15-bf69-407e-90f4-a86dcce7578a" config-ref="anypoint-mq-config" ackToken="#[vars.token]" />
</on-error-propagate>
The message is missing in the case of the DB:CONNECTIVITY error, as it should have been retried.
<on-error-propagate enableNotifications="true" logException="true" doc:name="On Error Propagate" doc:id="c4257397-7c81-4e15-af43-d4058cb4b086" type="DB:CONNECTIVITY">
<logger level="INFO" doc:name="Log Error" doc:id="0e3c852f-6140-454b-b43f-30154af15862" message="Error occurred while processing record:" />
<anypoint-mq:nack doc:name="Nack Message" doc:id="adc2c1d8-06a6-4b1b-be84-a704f263c923" config-ref="anypoint-mq-config" ackToken="#[vars.ackToken]"/>
</on-error-propagate>
This error strategy can be extended as per business requirements and use.
Using CurieTech AI’s Repository Coder to ensure reliability more easily
CurieTech AI tools are designed to build new flows and enhance and optimize existing ones. For instance, the Repository Coder tool can identify and apply missing configurations such as circuit breakers, redelivery, and error handling. Users can quickly strengthen their codebases by following a step-by-step prompt, ensuring greater reliability and best-practice compliance with minimal manual intervention.
Let's look at an example with the Repository Coder in action.
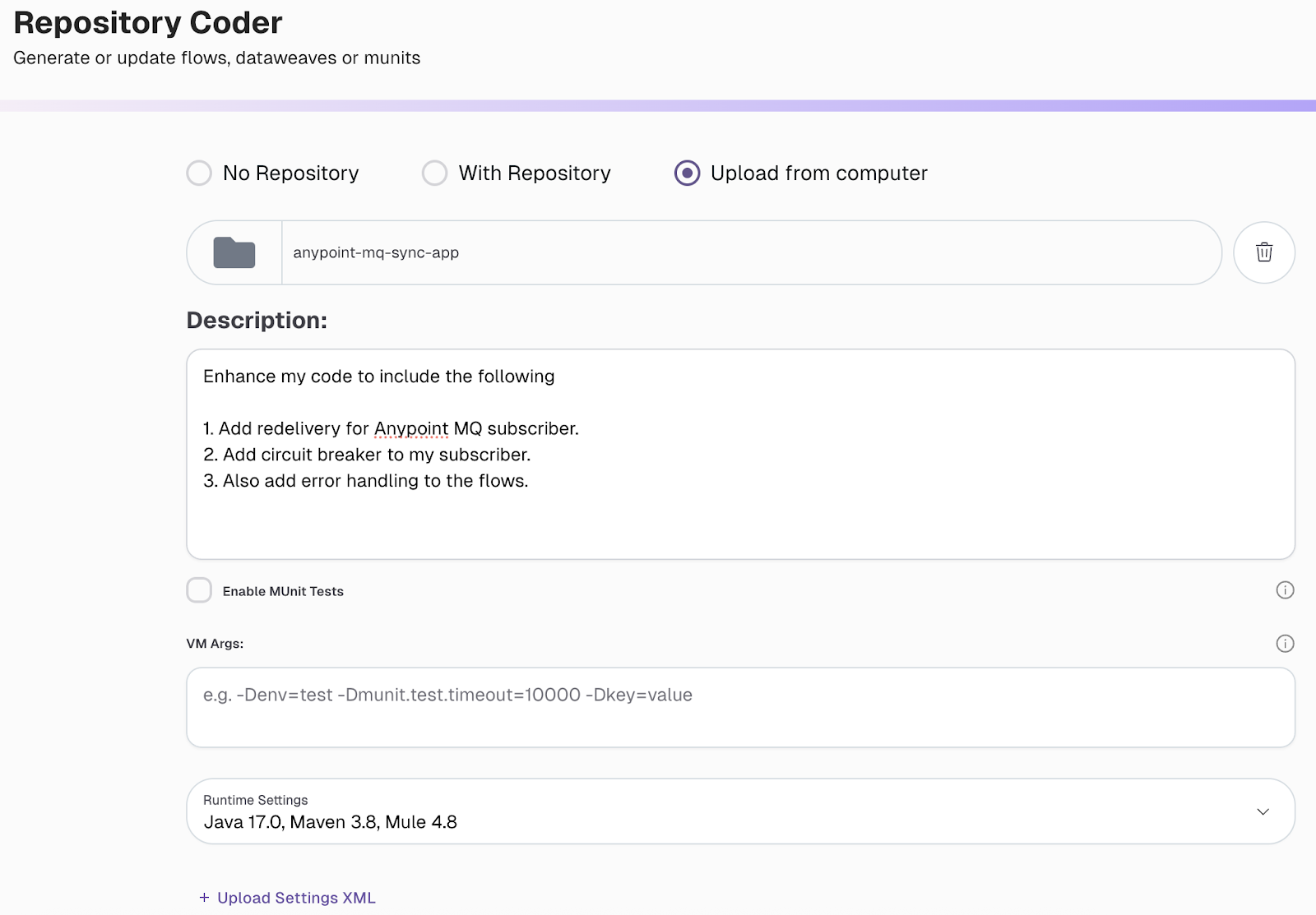
The Repository Coder tool adds the circuit breaker and redelivery configurations to the code. If something in the code is not as requested, you can request further changes by adding your changes in a comment. Here is the task completion snapshot.
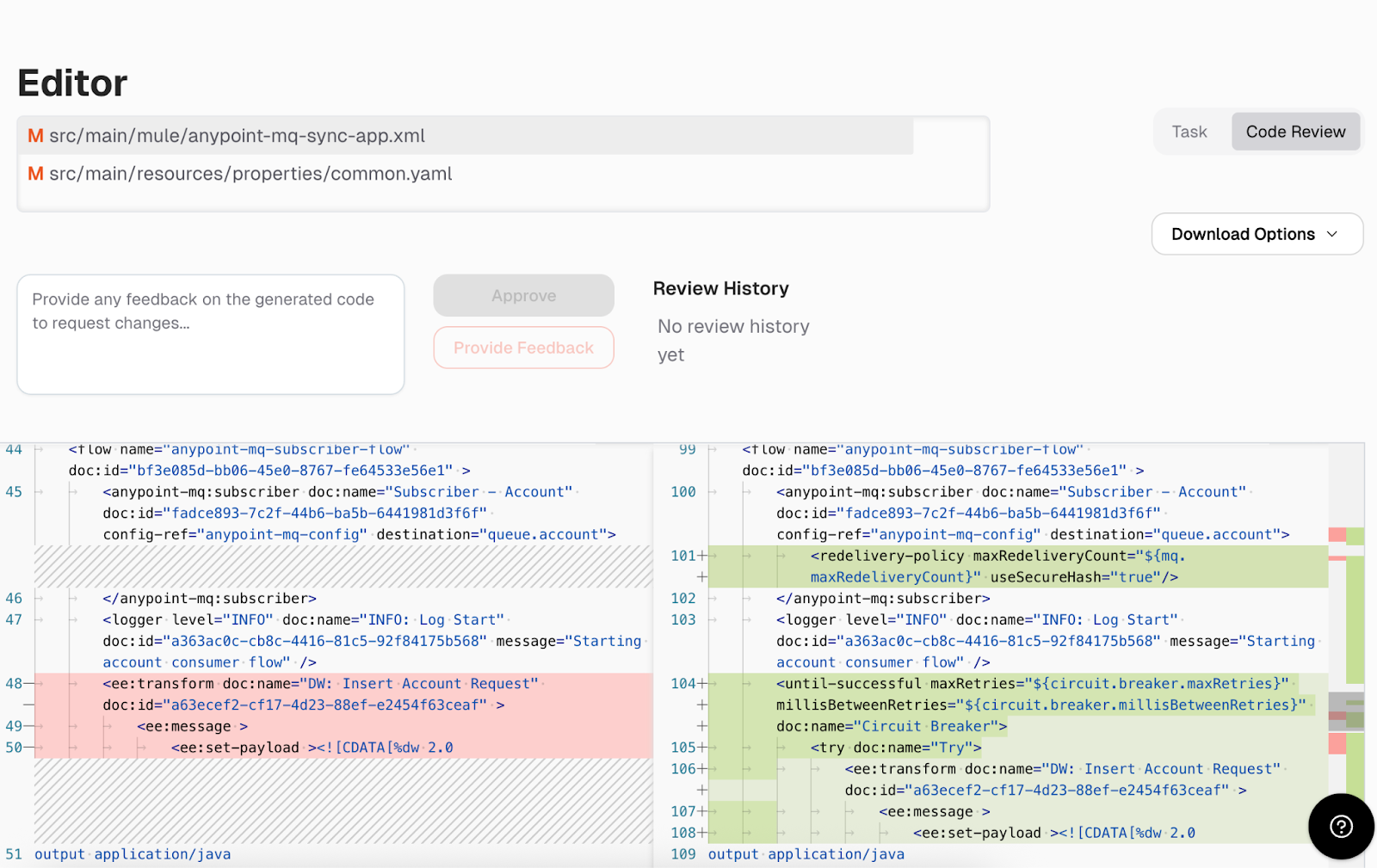
The tool added the redelivery policy and the circuit breaker configurations with externalized properties as given in the prompt.
Limitations and considerations
While Anypoint MQ has many benefits for creating asynchronous applications, it also has some limitations and considerations that should be discussed while architecting the solution. Here are some of them:
- Region restrictions: Anypoint MQ is not available in all regions. To reduce latency when creating queues in the Anypoint Platform, ensure you make them in the closest area. This ensures no extra delays while loading and unloading messages from a queue.
- Message size limit: The maximum message payload size supported by Anypoint MQ is 10 MB. If larger payloads need to be supported, the process application must split the payload into smaller chunks before publishing to the queue. Furthermore, payloads greater than 10 MB can be offloaded to blob storage, and messages with pointers to specific blobs can be published to the queue. The consumer can then consume the message and download the payload from the blob storage. However, applications must handle all this handling of payloads to support messages greater than 10 MB.
- TTL and retention: The time-to-live value determines how long a message remains in the queue before it is discarded; the default for a message in Anypoint MQ is 14 days. The default acknowledgement timeout can be set up to 12 hours, meaning that if the consumer does not acknowledge the message within 12 hours, it will be requested for processing.
- Rate limits: Depending on the Anypoint subscription, Anypoint MQ is subject to rate limits, allowing you to process only a specific number of requests in a particular timeframe. Before integrating Anypoint MQ in the architecture, ensure that your current Anypoint subscription allows enough bandwidth to process the expected number of messages in peak hours.
- Missing topic exchange and dynamic binding: Anypoint MQ can bind multiple queues to a message exchange based on routing rules. Still, it doesn’t support full AMQP-style topic exchange with advanced wildcard/topic-based routing. Also, Anypoint MQ doesn’t support dynamic binding at runtime; queues in AMQP topic exchange can bind or unbind to topics dynamically using routing keys. In Anypoint MQ, the bindings are static and configured before deployment.
Best practices
When developing applications that communicate with Anypoint MQ, it is essential to design and develop them using best practices to ensure that integrations are easier to maintain, scalable, and fault-tolerant. Here are some key practices to follow.
Design for idempotency
Always ensure that applications can process the same message more than once without impacting downstream systems. This is important because when using standard Anypoint MQ queues, Anypoint MQ follows at-least-once message delivery, meaning messages may be redelivered in case of failure. It is highly recommended that duplicate checks be implemented before processing messages from Anypoint MQ.
Use DLQs and redelivery
Anypoint MQ automatically retries failed messages, depending on the configuration. Enabling message redelivery protects against failures from downstream services.
Furthermore, as discussed earlier, you will want to configure dead letter queues: special queues where messages are sent if they aren’t successfully processed after a set number of retries. DLQs isolate problematic messages that can cause repetitive failures without affecting the main flow. Furthermore, you can enable failover on standard queues, ensuring that if the queues go down in the preferred region, your application can still connect to failover queues in a different area to continue processing.
Document messaging flows
Documenting flows helps your team understand how messages move among producers, queues, and consumers. It's essential to document architectural decisions made while choosing a specific type of queue, the expected volume, limitations, and assumptions for asynchronous messaging apps. Documentation is a handy tool, especially when looking into complex integrations, to understand and deduce failures in messaging applications at the time of failures.
Documentation has become more straightforward thanks to tools like CurieTech AI’s Document Generator. Instead of writing everything from scratch, you can automatically generate clear, detailed documentation by providing the flow. The tool can produce a sequence, flow diagram, and well-structured descriptions of each step, all with minimal manual input.
Here is an example of the document and sequence diagram generated using the Document Generator tool for the example used in this article.
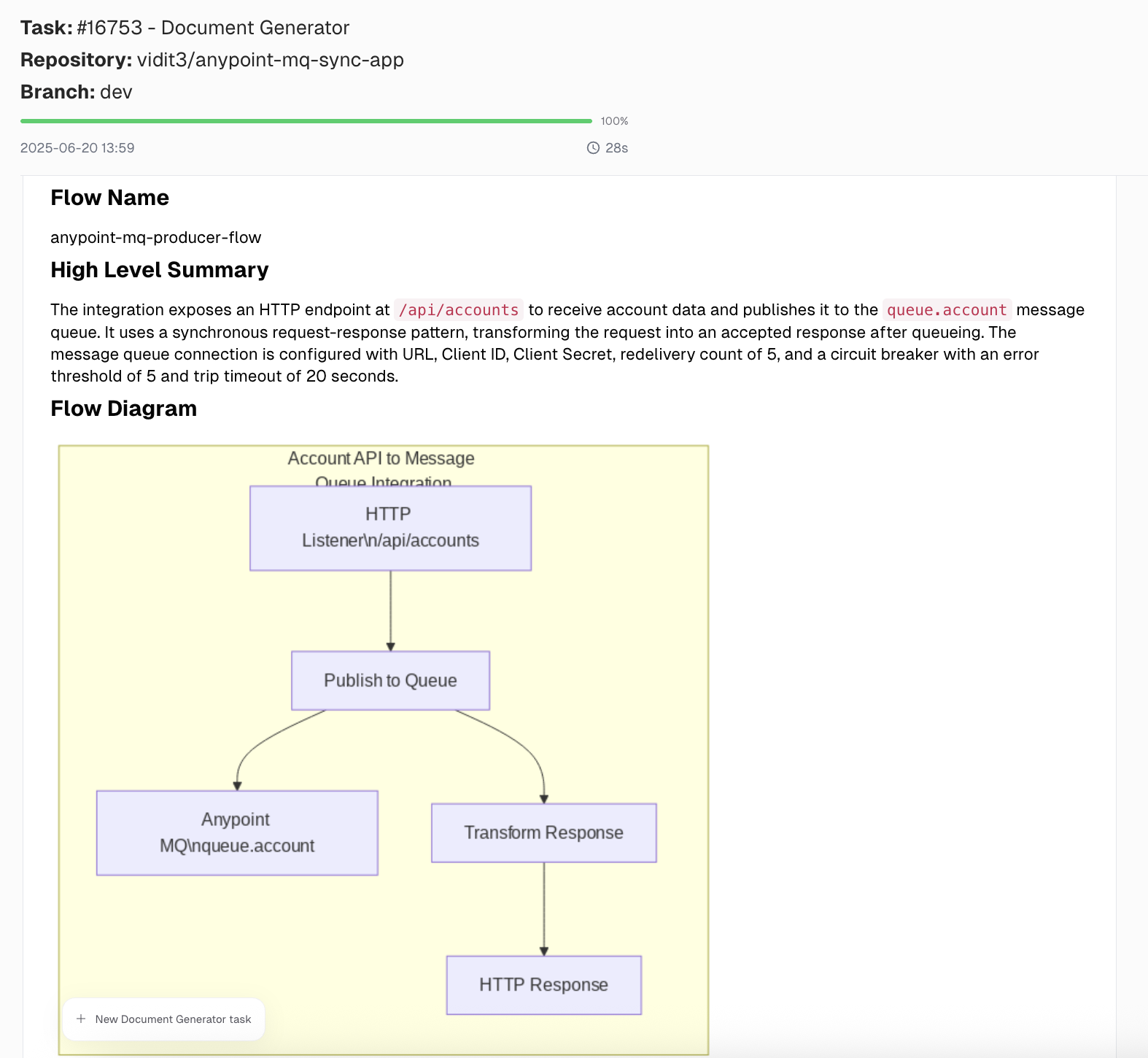
Choose the correct queue type
It is essential to choose the right queue type based on your requirements. For example, if message order is necessary, you need FIFO queues; conversely, if it is not essential while consuming and processing records, standard queues are a better choice because they allow high throughput and parallelism.
Handle back pressure
There might be situations when consumers are overwhelmed as producers send messages quickly. Configure multiple consumers for a queue to ensure the load is distributed and no one worker is overwhelmed with requests beyond its bandwidth. Scale applications and consumers as per load. Always design solutions that can handle three to four times the number of peak-hour requests.
Remember security
To ensure data integrity and prevent accidental misuse of queues, enable role-based access control to restrict what each app/client can do depending on their permission set. Use a connected app to connect and manage queues from applications, and always use secure properties, externalized configs, or a secret manager.
Avoid tight coupling
Never design your producers and consumers to depend on each other’s internal logic or timing. Keep these working independently, where the producer can produce messages irrespective of the consumer, and vice versa. Loose coupling allows independent scaling, failure recovery, and simplified maintenance.
CurieTech AI’s Code Review Agent
The Code Review feature from CurieTech AI can be used to gain insights into code. You can ask the Code Review agent to review all code configurations and give suggestions for best practices, error handling, etc. Code Review can speed up the process of code reviews by curating suggestions, best practices, flow considerations, logging, error handling improvements, and any security vulnerabilities.
Here is a demonstration of how the Code Review agent works to identify all the issues within your codebase.
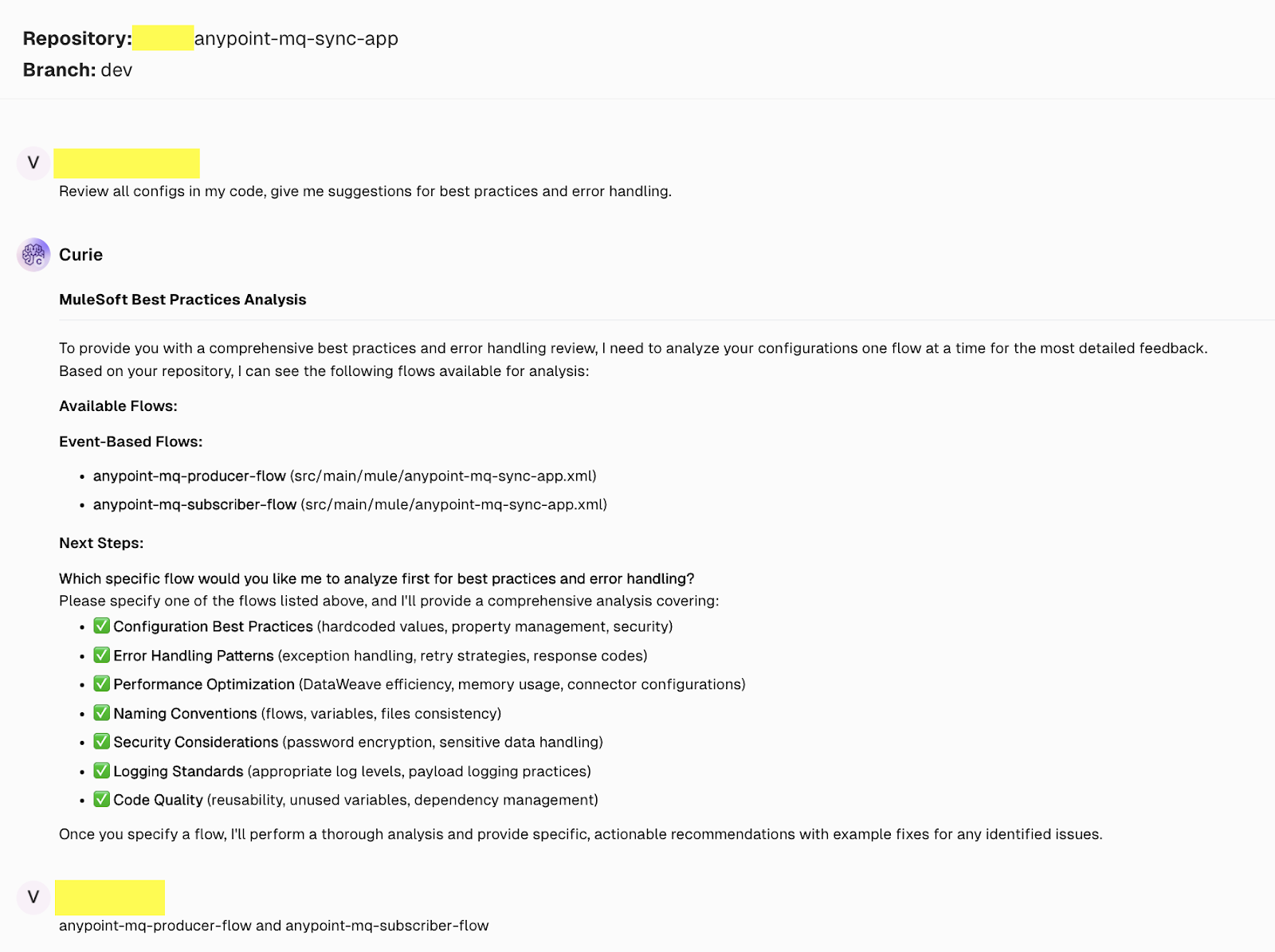
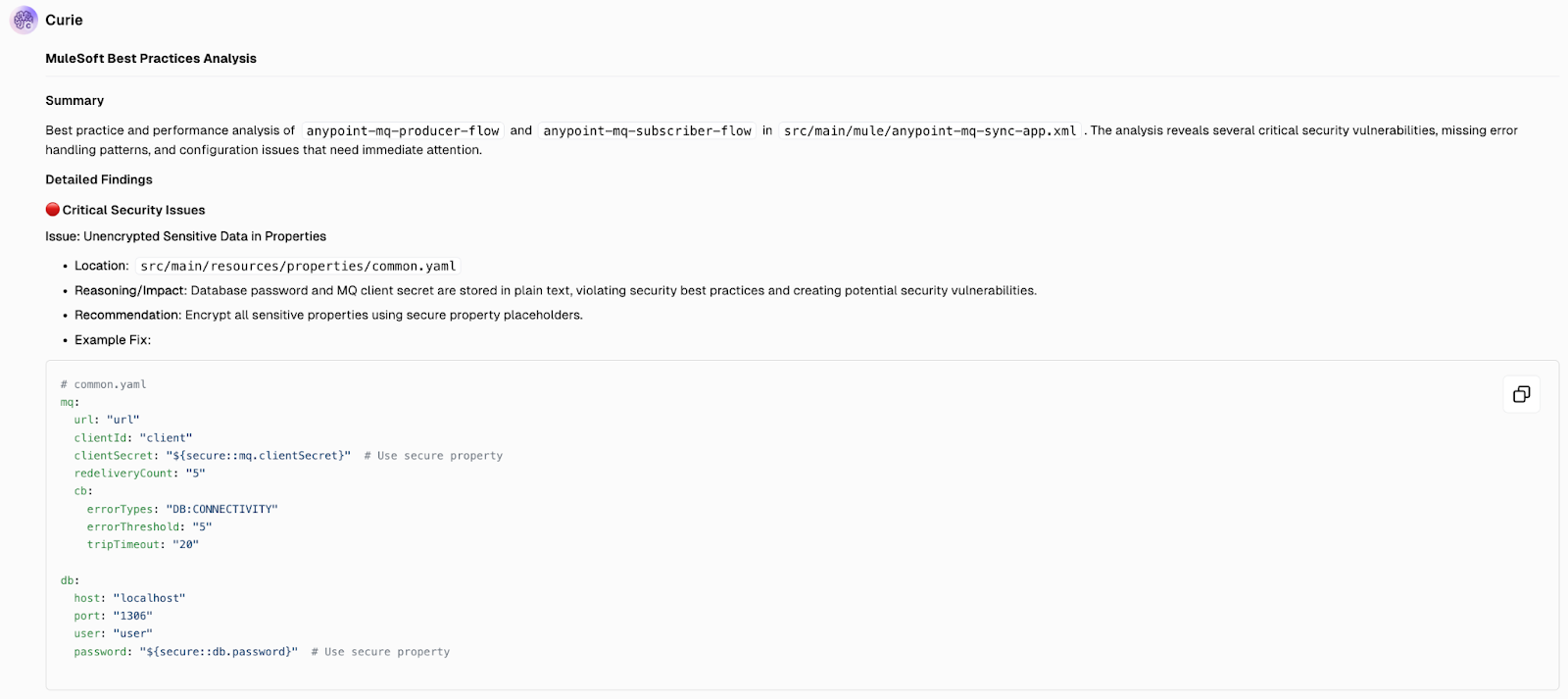
The Code review agent lists all the issues with the specified flows and provides a comprehensive and detailed summary of all considerations.

{{banner-large-table="/banners"}}
Conclusion
This article discussed the core concepts of messaging queues, particularly Anypoint MQ. We explored the concepts behind Anypoint MQ, its features, and how to build a secure, safe, and fault-tolerant application. In addition, we looked at practical design considerations, real-world use cases, and best practices that can help teams effectively integrate Anypoint MQ into their architecture. With thoughtful implementation, Anypoint MQ can be a reliable foundation for enabling scalable, asynchronous communication across distributed systems.