

Following our previous analyses comparing the CurieTech AI agent to the MuleSoft Dev Agent and GitHub Copilot, this post extends our benchmark to include a new participant: Cursor, an AI-powered code editor.
To ensure our evaluation reflected integration challenges, we defined a benchmark of 80 real-world tasks of different complexities. You can find a detailed description of our benchmark and methodology in our first post. Our metric for success remains strict: the generated code must fully implement all requirements and pass all syntax and unit tests on the initial attempt, without needing any manual adjustments. This "first-time success" rate serves as a direct indicator of an AI agent's ability to enhance developer productivity.
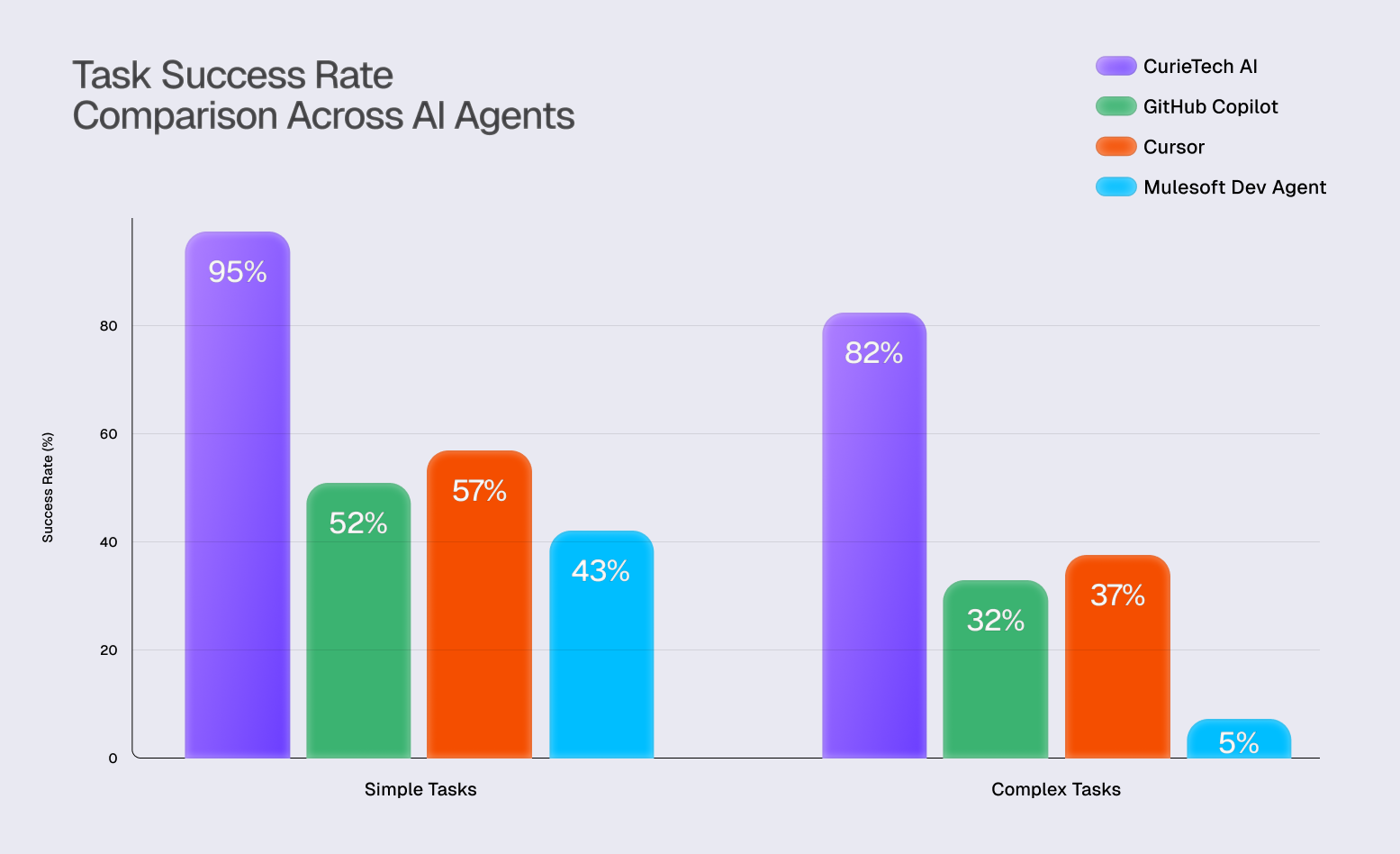
Quantitative Analysis: A Widening Gap in Performance
The results of our expanded benchmark continue to highlight a significant performance disparity between specialized and general-purpose AI tools, especially as the complexity of tasks increases.
For simple tasks, Cursor achieved a 57% success rate. This positions it slightly ahead of GitHub Copilot's 52% and notably better than the MuleSoft Dev Agent's 43%. However, the specialized CurieTech AI Agent maintained its lead with a 95% success rate.
On complex tasks, the performance gap became more pronounced. The CurieTech AI Agent sustained a high success rate of 82%. In contrast, Cursor's success rate dropped to 37%, followed closely by GitHub Copilot at 32%. The MuleSoft Dev Agent's performance was significantly lower, with a 5% success rate.
These figures indicate that while advanced general-purpose editors like Cursor show competence in simpler scenarios, their effectiveness diminishes when faced with the complicated, multi-faceted challenges common in enterprise-level MuleSoft projects.
Qualitative Analysis: Examining Common Pitfalls
The types of errors generated are as insightful as their frequency. Our analysis of Cursor's output identified several distinct failure patterns. While some issues were unique to Cursor, others were recurring problems we also observed in other general-purpose tools.
New Error Patterns
We observed the following issues that were not prevalent in our previous analysis of GitHub Copilot:
Over-engineering and Instructional Deviations: Cursor sometimes added unrequested code, such as verbose loggers. In high-performance integration scenarios, such additions can unnecessarily bloat logs and complicate debugging, representing a failure to adhere strictly to the task requirements.
Incomplete Configuration Updates: A recurring issue involved the agent adding new properties to local YAML files without declaring them in the global configuration. This oversight highlights a lack of awareness of the project's structure, leading to deployment failures.
Recurring Issues in General-Purpose Tools
Cursor also repeated some of the same domain-specific mistakes we saw in other tools, demonstrating a common weakness among non-specialized agents:


These errors, whether new or recurring, point to a lack of deep, domain-specific understanding of the MuleSoft ecosystem. Such issues can be particularly time-consuming for developers to diagnose and rectify, potentially offsetting the initial time saved by AI-powered code generation.
Conclusion: The Enduring Value of Specialization
For the highly specialized field of MuleSoft development, a purpose-built tool like the CurieTech AI Agent demonstrates superior accuracy and reliability compared to even the most advanced general-purpose AI code editors. A success rate of 82% on complex tasks, in contrast to Cursor's 37% and GitHub Copilot's 32%, translates into substantial savings in development time and a significant reduction in debugging cycles. For organizations focused on building and maintaining mission-critical integrations, a specialized AI agent is the most effective path to realizing genuine productivity improvements.
The article is co-authored by Dmitry Yashunin, Achyut Kulkarni.

.png)

