

Following our previous analysis, this post extends our benchmark to include GitHub Copilot, comparing its performance against the specialized CurieTech AI Agent and the native MuleSoft Dev Agent. To ensure a fair comparison against the best general-purpose tools, we tested GitHub Copilot using one of its most advanced available models for software engineering, Anthropic's Claude 4.5 Sonnet. The testing setup remains identical to our last post, using a suite of 80 representative tasks (both simple and complex) drawn from real-world MuleSoft projects.
Our metric for success is strict and practical: the generated code must precisely follow all instructions and pass all syntax and unit tests on the first attempt, without any manual intervention. This "first-time success" rate is the most direct measure of an AI agent's impact on developer productivity.
Quantitative Analysis: Performance by Task Complexity
The results reveal a significant performance gap between the specialized CurieTech AI Agent and a general-purpose tool like GitHub Copilot, particularly as task complexity increases.
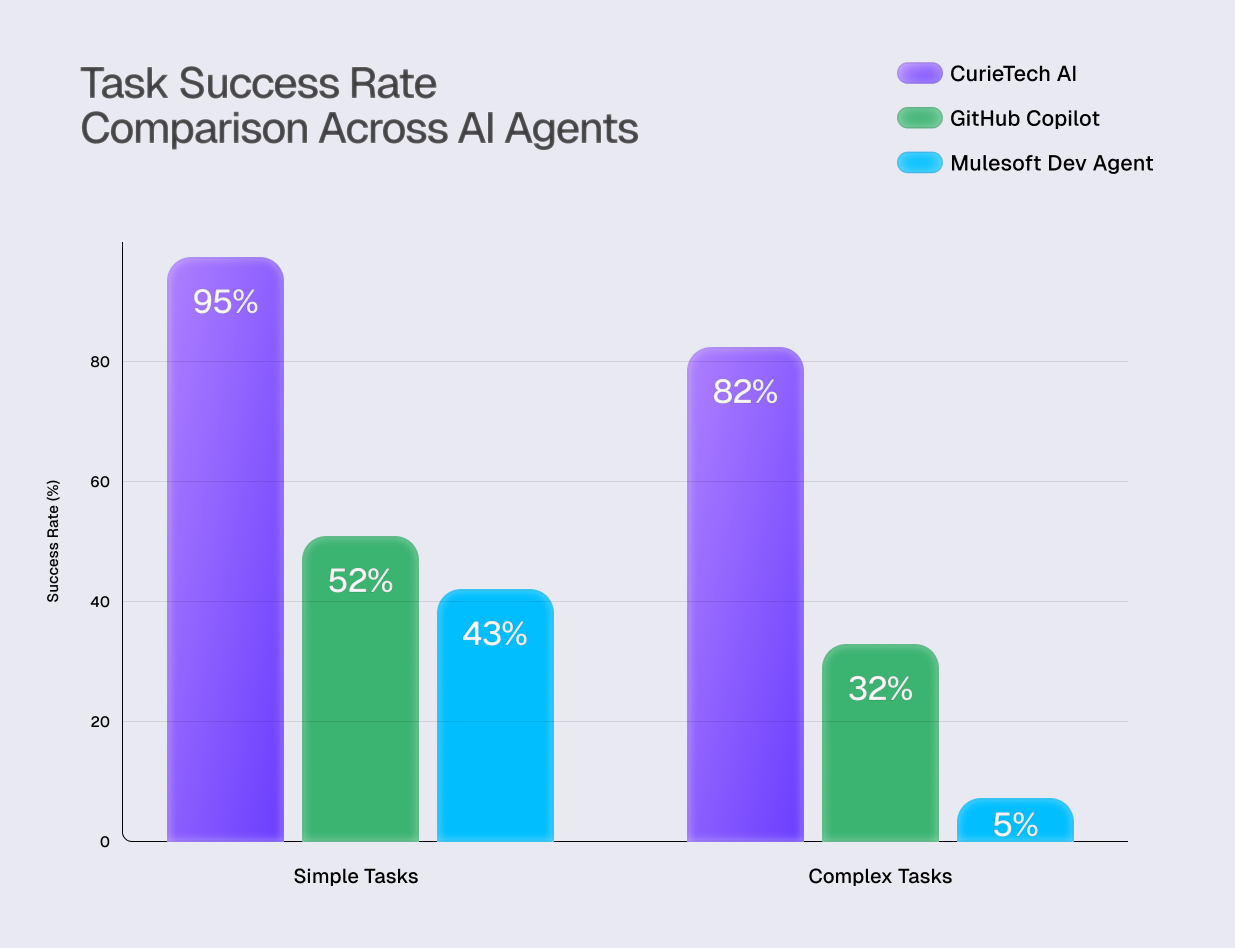
Simple Tasks: GitHub Copilot achieved a 52% success rate. In comparison, the specialized CurieTech AI Agent reached 95%, while the MuleSoft Dev Agent scored 43%.
Complex Tasks: The performance disparity widened significantly. GitHub Copilot's success rate fell to 32%, while the CurieTech AI Agent maintained a high performance of 82%. The MuleSoft Dev Agent succeeded in only 5% of cases.
These numbers show that while GitHub Copilot, powered by a state-of-the-art model, has a respectable average accuracy of 45%, its reliability drops sharply on the complex, multi-faceted tasks common in enterprise integration projects.
Qualitative Analysis: A Look at Common Errors
The nature of the errors is as important as their frequency. The majority of GitHub Copilot's failures stem from wrong connector schemas, not following instructions, and DataWeave syntax errors. See the examples below.



Notably, these errors are more sophisticated than the clear hallucinations or incomplete files sometimes produced by the MuleSoft Dev Agent. GitHub Copilot’s errors often appear syntactically plausible, making them harder and more time-consuming for a developer to debug.
Conclusion
For the specialized domain of MuleSoft development, a purpose-built tool like the CurieTech AI Agent is demonstrably more accurate and reliable than a general-purpose tool like GitHub Copilot. The performance gap is significant. A success rate of 82% on complex tasks, compared to just 32% for Copilot, translates directly into saved development time and reduced debugging cycles. For teams building mission-critical integrations, a specialized AI agent is the key to achieving true productivity gains.
The article is co-authored by Dmitry Yashunin, Achyut Kulkarni, Apoorv Sharma, Parth Dodhia, and Jian Vora.

.png)

