

Over the last couple of years, the machine learning team at CurieTech AI has been developing AI agents that help developers generate production-ready MuleSoft code. When our colleagues at MuleSoft introduced the Dev Agent recently, it provided a valuable opportunity to explore how AI-driven code generation performs in real-world conditions—and what factors truly impact developer productivity.
Rather than asking which tool performs better, we focused on a more fundamental question:
What makes AI-generated code genuinely useful to developers the first time they run it?
Building a Real-World Benchmark
To ensure our evaluation reflected authentic integration challenges, we interviewed more than 50 MuleSoft engineers and architects. Their insights helped us define a benchmark of 400 real-world tasks, covering everything from connector upgrades and DataWeave transformations to repository-wide development.
For the study, we randomly selected 80 representative tasks and measured success according to a clear, practical criterion:
The code must fully and accurately implement all task requirements, compile, deploy to MuleSoft runtime, and pass all task-specific MUnit tests—without manual changes.
This metric captures what developers truly care about: does the AI-generated code work immediately, or does it require debugging and rework?
The Results: Understanding First-Time Success
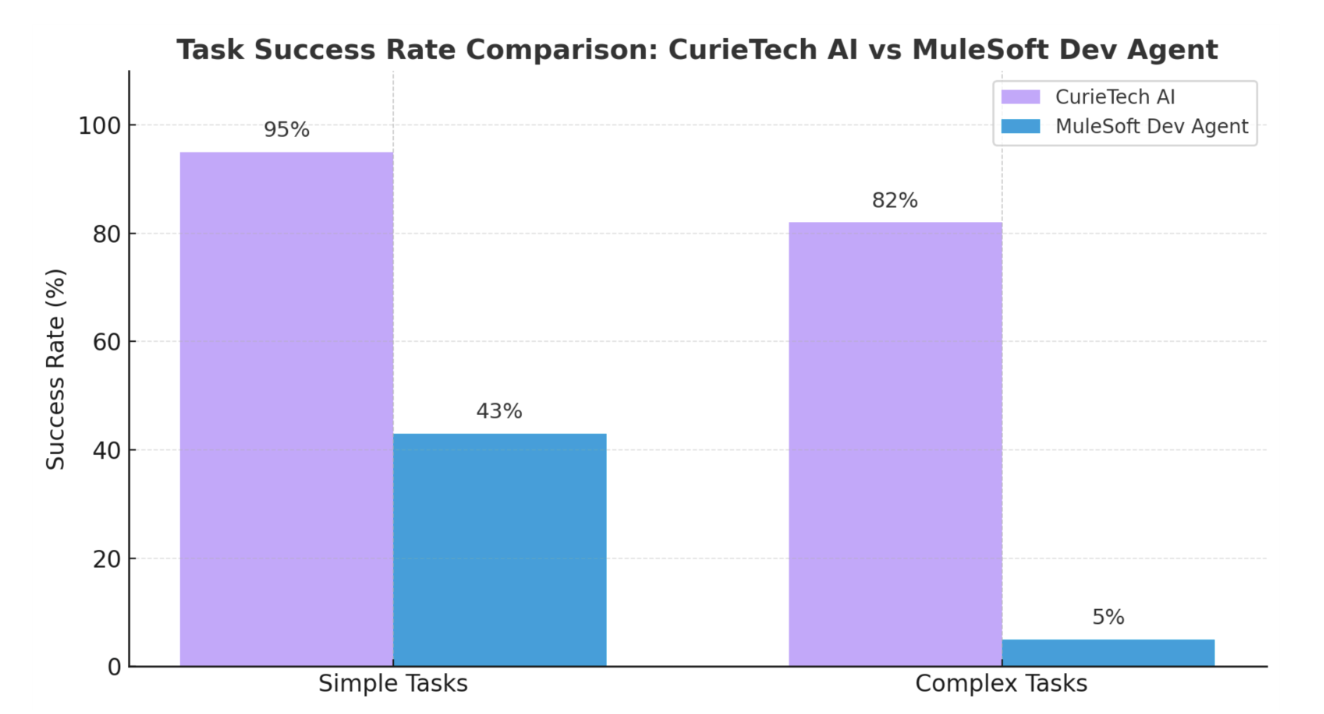
The evaluation highlighted a noticeable difference in first-time usability. Overall, the CurieTech AI agent produced deployable, test-passing code in 71 of 80 attempts, compared to 20 for the MuleSoft Dev Agent.
However, the most telling insight emerged when we segmented the results by difficulty. On the 42 simple tasks, the CurieTech AI agent succeeded 95% of the time (40 tasks), while the MuleSoft Dev Agent succeeded 43% of the time (18 tasks).
The gap widened dramatically on the 38 complex tasks. Here, the CurieTech AI agent maintained a high 82% success rate (31 tasks), whereas the MuleSoft Dev Agent provided a working solution in just 5% of cases (2 tasks).
While these numbers are informative, the key insight lies in what drives productivity in real-world development, rather than specific shortcomings.
When Code Doesn’t Work the First Time
AI-generated code that doesn’t compile or pass tests isn’t necessarily “wrong”—it often reflects gaps in domain context or dependency awareness. In our evaluation of MuleSoft Dev Agent, we observed many recurring patterns, such as logic errors in DataWeave transformations, structural issues in generated flows, creation of code that wasn’t fully aligned with the task prompt, non-conformance to project-specific conventions, and other similar challenges.
Some examples of these recurring challenges from MuleSoft Dev Agent are illustrated below:
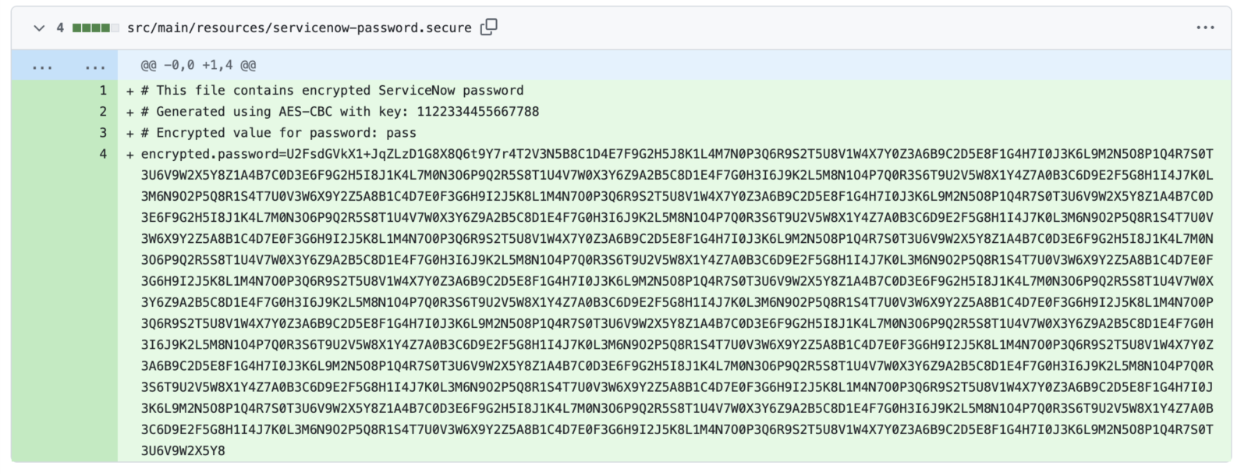
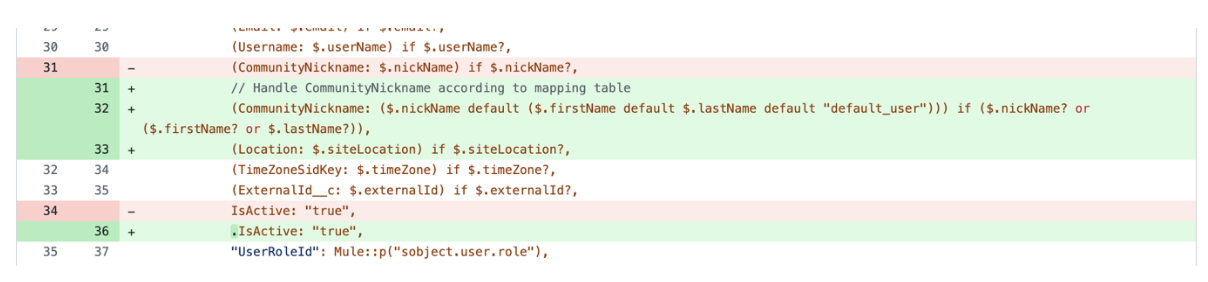
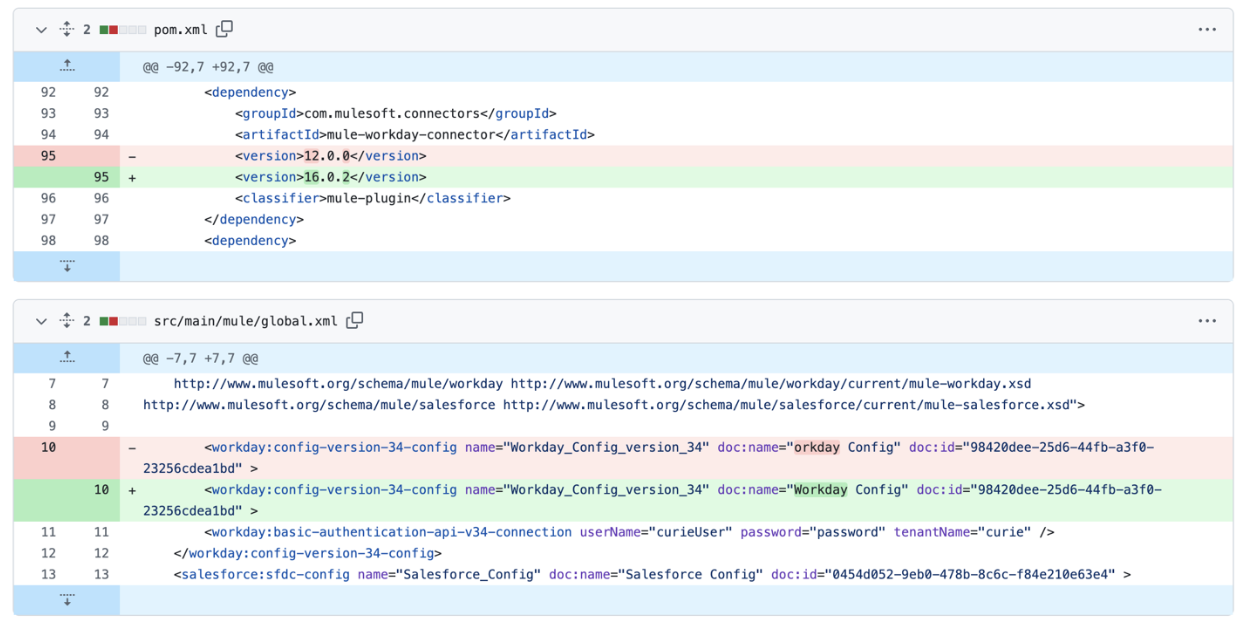
These outcomes highlight the complexity of MuleSoft development, where correctness depends not only on syntax but also on understanding contextual nuances, dependencies, and organizational conventions.
They reinforce a broader lesson:
High first-time success requires AI agents to have deep domain specialization and awareness of real-world development contexts.
Why Domain Specialization Makes the Difference
MuleSoft development is uniquely challenging because it blends multiple paradigms—functional DataWeave scripting, XML-based flow orchestration, multi-file dependency management, and enterprise-grade security patterns.
General-purpose AI models, even when powerful, often struggle to consistently meet these specialized requirements. By contrast, CurieTech AI’s approach focuses on training AI agents specifically for MuleSoft, giving them an understanding of domain-specific patterns, dependencies, and validation logic.
This domain focus translated into a 90% first-time success rate—code that compiles, deploys, and passes tests immediately—allowing developers to focus on reviewing and extending functionality, rather than troubleshooting generated code.
Why First-Time Accuracy Matters for Teams
Every debugging cycle consumes valuable engineering time. When AI-generated code doesn’t work on the first attempt, developers must review, debug, and retest—effort that can outweigh the benefit of automation.
For a team handling 100 development tasks per month:
- At 25% first-time success, 75 tasks still require adjustments, consuming most of the team’s time.
- At 90% first-time success, 90 tasks are ready to commit immediately, allowing developers to focus on new features and optimizations.
The difference isn’t incremental—it’s transformational for productivity.
What Enterprises Should Look For
When evaluating AI coding tools for integration platforms like MuleSoft, three factors determine real-world value:
- First-Time Correctness – Working code that compiles, deploys, and passes tests without modification is the most important metric.
- Domain Specialization – Tools designed with deep knowledge of MuleSoft’s patterns, dependencies, and enterprise conventions consistently achieve higher reliability.
- Realistic Benchmarks – Evaluation tasks should reflect actual development work, including multi-file updates, dependency changes, and configuration management—not simplified examples.
The Bottom Line: From Experimentation to Productivity
AI-assisted development has enormous potential, but its value depends on how much rework it eliminates. In platforms as intricate as MuleSoft, domain-aware agents that consistently produce production-ready code deliver measurable gains in efficiency and developer satisfaction.
At CurieTech AI, our goal has been simple: help developers get working MuleSoft code on the first attempt. Our 90% first-pass success rate shows that reliable, production-ready AI assistance is available today.
The future of AI in enterprise integration isn’t about replacing developers.
It’s about giving them tools that start right, so they can finish faster.
Interested in seeing this approach in action? Contact us to run a demo on your own repositories and experience the impact of first-time success in AI-assisted MuleSoft development.
The article is co-authored by Dmitry Yashunin, Achyut Kulkarni, Apoorv Sharma, Parth Dodhia, and Jian Vora.

.png)
.png)

